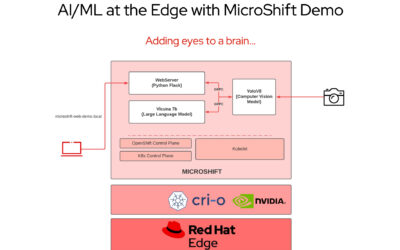
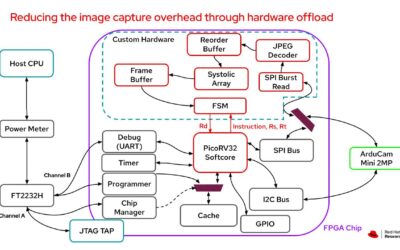
By Gordon Haff
Given today’s focus on extracting information and value from large data sets, it shouldn’t be a surprise that data-intensive science is an area of active research in both academia and industry. That’s why it was one of the tracks at Red Hat Research Day held in Brno, Czech Republic last January. (Security & Privacy and Code Analysis & Verification were the other two.)
Data-intensive science involves software certainly, but it also needs the right hardware platforms, which increasingly also means low-level hardware optimizations and accelerators of various types.
Open Cloud Testbed
With respect to hardware research, Michael Zink of the University of Massachusetts at Amherst led off Research Day with a discussion of the National Science Foundation-funded Open Cloud Testbed (OCT) project which integrates testbed capabilities into the Mass Open Cloud (MOC).
Launched in 2014, the MOC runs at the Massachusetts Green High Performance Computing Center (MGHPCC) in Holyoke. It’s a collaboration of academia, industry, and the state with overall project leadership provided by Boston University. Its objective is to enable cloud-related systems research as well as serving as a production platform that isn’t locked into a single public provider. It’s built on the Red Hat OpenStack Platform and uses Ceph for its storage foundation.
One of the issues with using commercial public clouds for certain types of computer science and engineering research is that a cloud abstracts away many of its physical underpinnings. This can prevent users from accessing data they may need for research purposes, for example telemetry data about power consumption.
A testbed running in the MGHPCC allows greater access to low-level hardware and software than is possible with commercial public cloud offerings. OCT will also provide field-programmable gate arrays (FPGAs) for researching configurations such as Bump-in-the-Wire, which can be used to perform functions such as encryption on real-time network links.
Making Sense of Big Data
Other sessions were more focused on the data itself.
Gabriel Szász, a graduate student at Masaryk University in Brno, together with a team from Red Hat, talked about their collaborative project using Red Hat OpenShift Container Platform for high-performance computing. Szász is studying the effects of rotation on the measured properties of stars, work that is in the field of quantitative spectroscopy, one of the cornerstones of modern astrophysics. This is part of research into the stellar atmosphere model grid.
One of the challenges with this work is that a number of the software components that are used in the course of spectroscopy calculations are very old and often written in languages like FORTRAN and Ada. But rewriting them would be time consuming and the rewrites would probably not be accepted by the research community anyway.
OpenShift provides a way to containerize these components while providing a modern developer experience for new code and metrics and dashboards through Prometheus and Grafana. OpenShift also provides the flexibility to run the workloads (and store the 100TB or more of data) on different types of hardware infrastructure as needed.
Another data-related session, “Acoustic Identification of Cetaceans,” came from Georgia Atkinson, a Ph.D. candidate studying bioacoustics at Newcastle University in the United Kingdom. Cetaceans (which include porpoises, dolphins, and toothed whales) are typically top predators in their environment so their health and numbers tells us a great deal about the health of the marine ecosystem as a whole. One of the techniques for identifying many types of cetaceans is passive acoustic monitoring (PAM) that can distinguish individuals even within the same species by their signature whistles. This talk highlighted the challenges associated with finding the meaningful signals, the signature whistles in this case, among the nine months of ambient sounds collected by three hydrophones.
Techniques included converting the audio to spectrograms that make it easier to detect distinctive frequencies, taking advantage of crowd-sourced dolphin sightings to pinpoint times of particular interest, and filtering samples by the amount of potentially interesting frequency sounds present. It was a useful reminder that real-world data rarely comes clean and ready to use.
Wrap-Up
Research threads in systems engineering, high performance computing, and data analysis all feed into data-intensive science. This research can be enabled by commercial open source products such as Red Hat OpenShift Container Platform which provides a platform and simplifies development for scientists who are not necessarily computer scientists or software developers. At the same time, research into hardware accelerators and other approaches for optimizing system architecture and operations are advancing the state of the platform inself.
Video and audio:
Research Day Europe 2020 site including program and pointers to videos
Podcast: Open Cloud Testbed with UMass Amherst’s Michael Zink [15:29]