


















As organizations push LLMs into more consequential domains, trust becomes the foundation for scale. Engineers in the open source TrustyAI project developed a guardrailing solution to ensure open source LLMs are both capable and safe for high-stakes deployments.
Building trustworthy and controllable enterprise-grade LLM systems is challenging. These systems are increasingly being adopted across domains, yet their widespread deployment hinges on trustworthiness. A system is considered trustworthy if it behaves reliably within its use case, remains transparent to end users, and is aligned with human values. However, LLMs are inherently stochastic: they may generate factually incorrect or nonsensical content (hallucinations) and are susceptible to adversarial inputs through prompt injection. These risks make it critical to develop mechanisms that constrain both user inputs and model outputs to ensure safe and predictable system behavior.
This is precisely what guardrailing aims to do. Developers cannot guarantee full compliance with trustworthiness standards due to the probabilistic nature of LLMs, but they can reduce risk by bounding input domains and flagging problematic outputs. For instance, a business using a fine-tuned LLM on proprietary data may want to reject inputs that fall outside the model’s training scope and flag toxic or inappropriate generations to protect brand and users alike.
The TrustyAI Guardrails Orchestrator provides a practical solution. It lets users define custom guardrails that inspect input/output text for certain patterns—such as regular expressions or domain-specific markers—and can also run detections independently of inference. Based on the open source project FMS Guardrails Orchestrator and developed in collaboration with IBM Research, it is available on Red Hat OpenShift AI (RHOAI) 2.19+ via KServe RawDeployment mode.
In this way, the orchestrator brings enterprise LLM deployments closer to operational trustworthiness by offering a lightweight, inference-time control layer without retraining the model itself.
Architecture
Guardrailing LLMs using the orchestrator involves coordinating several components to enforce safety and policy controls at inference time. At its core, the solution addresses two key challenges: detecting problematic content and managing safe input/output flows through deployed LLMs. To tackle these, the architecture introduces two main component types: detector servers and the guardrails orchestrator service (Figure 1). Detector servers are REST services designed to evaluate input or output text against specific criteria, while the orchestrator coordinates inference and detection logic across the system.
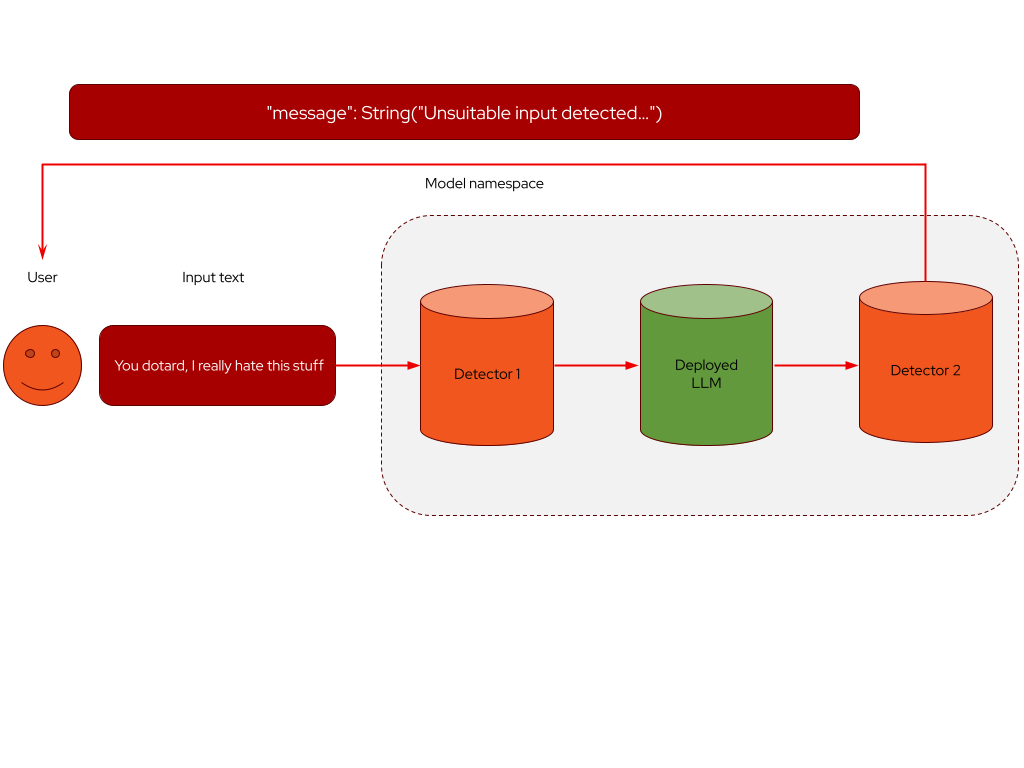
Currently, the platform supports two classes of detectors. First, Hugging Face detectors based on the generic AutoModelForSequenceClassification class or the GraniteForCausalLM family can be deployed on Hugging Face (HF) ServingRuntime. These are ideal for use cases such as toxicity classification. Second, TrustyAI-developed regex detectors match predefined patterns or custom expressions, such as social security numbers, credit card numbers, and email addresses, in plain text. These lightweight detectors provide a simple but effective control layer.
The orchestrator service manages routing between users, detectors, and the target LLM hosted on vLLM ServingRuntime. It optionally integrates a chunker service that splits long input texts into spans to help manage maximum token limits imposed by the model. This allows for fine-grained inspection and safer inference across variable-length content.
Deployed as a controller within the TrustyAI Kubernetes Operator, the orchestrator simplifies Kubernetes-based integration and benefits from OpenShift-native capabilities. It is built on the open source FMS Guardrails Orchestrator project, which provides span-aware detection pipelines configurable by the user for both pre- and post-inference workflows.
The Guardrails Orchestrator introduces a new Kubernetes Custom Resource Definition (CRD) called GuardrailsOrchestrator. When a GuardrailsOrchestrator Custom Resource (CR) is applied to a namespace, it provisions the necessary components to monitor user interactions with the deployed LLM. Depending on the API request, it runs detections on user inputs, model outputs, or both. Specifically, the CR creates a deployment that launches a pod running the Guardrails Orchestrator as a container. This deployment is exposed via a Kubernetes Service, which is assigned an external route, allowing users to query the orchestrator from outside the OpenShift cluster (Figure 2).

The external route provides several endpoints for running detections on model inputs, outputs, or standalone text. A full list of supported endpoints is available in the fms-guardrails-orchestrator APIs. Figure 3 illustrates the structure of a detection payload, where input and output detection rules are defined directly within the request body.
curl -X 'POST' \
'http://${GORCH_ROUTE}/api/v2/chat/completions-detection' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "llm",
"messages": [
{
"content": "You dotard, I really hate this stuff",
"role": "user"
}
],
"detectors": {
"input": {
"hap": {}
},
"output": {
"hap": {}
}
}
}’Figure 3. The structure of a detection payload
Suppose a user has deployed a model named “llm” on vLLM Serving Runtime and a detector named “hap” that detects Hateful and Profane (HAP) content on a custom HF ServingRuntime. The user sends a POST request to the api/v2/chat/completions-detection endpoint, specifying the name of the deployed model, input text, and detectors. Since both inputs and outputs are included in the payload, HAP detection is applied to both the user prompt and the model’s response. Upon receiving the request, the orchestrator first sends the input to the HAP detector. If HAP content is detected, it sends a warning to the user in the response and blocks the input from reaching the model, thus preserving the model’s trustworthiness. If no issues are found, the orchestrator passes along the input to the deployed LLM. The LLM generates an output which is then passed to the detectors to flag for HAP content. Again, if HAP content is detected, the user will receive a warning response and no results from the model. Otherwise, the generated output is returned to the user.
Configuration details
To configure the GuardrailsOrchestrator in RHOAI, the Custom Resource must, at a minimum, reference a ConfigMap, a Kubernetes resource that stores configuration data as key-value pairs. The ConfigMap defines key deployment parameters, including the number of replicas for the deployment to spin up (Figure 4) and the location of the LLM and detector services (Figure 5).
---
apiVersion: trustyai.opendatahub.io/v1alpha1
kind: GuardrailsOrchestrator
metadata:
name: gorch-example
spec:
orchestratorConfig: "fms-orchestr8-config-nlp" <1>
replicas: 1 <2>Figure 4. Defining deployment parameters
---
apiVersion: v1
kind: ConfigMap
metadata:
labels:
app: fmstack-nlp
component: fms-orchestr8-nlp
deploy-name: fms-orchestr8-nlp
name: fms-orchestr8-config-nlp
data:
config.yaml: |
chat_generation: <1>
service:
hostname: llm-predictor.test.svc.cluster.local
port: 8080
detectors: <2>
hap:
type: text_contents
service:
hostname: guardrails-detector-ibm-hap-predictor.test.svc.cluster.local
port: 8000
chunker_id: whole_doc_chunker <3>
default_threshold: 0.5Figure 5. Defining specific detectors
As shown in Figure 4, first, the orchestratorConfig field specifies a ConfigMap object that contains generator, detector, and chunker arguments. Second, The replicas field specifies the number of GuardrailsOrchestrator pods. By default, it is set to 1.
Users can define specific detectors on the ConfigMap under the detectors field. In Figure 5, the Generation field specifies the hostname and port of the LLM service, and the Detectors field specifies the hostname and port of the detector service, the chunker ID, and the default threshold.
Additional configurations
Since RHOAI 2.19, support has been added for additional detector types and a vLLM gateway adapter, enabling broader enterprise use cases. Both components are sidecar containers, injected into the orchestrator pod at deployment time. They can be used individually or in combination. The regex detectors are lightweight HTTP servers designed to parse text using predefined patterns or custom regular expressions. They serve as drop-in replacements for model-based detectors and include built-in support for detecting social security numbers, credit cards, and email addresses.
The vLLM gateway adapter assigns a unique /v1/chat/completions endpoint for each configured detector server. This enforces stricter access over the orchestrators’ endpoints, enabling more granular policies.
For more detailed setup instructions, including how to configure the GuardrailsOrchestrator with these optional add-ons and to structure the detector payloads, please refer to the GuardrailsOrchestrator documentation.
What’s next?
The Guardrails Orchestrator is available on RHOAI 2.19+ through the TrustyAI Service Kubernetes Operator, and we welcome any community feedback regarding its functionality and components. Contributions, including issues and pull requests, can be submitted to the TrustyAI Service Operator GitHub repository, and we are actively developing an integration with Meta’s LlamaStack by supporting the orchestrator as a remote safety provider via the TrustyAI Guardrails LlamaStack Provider.
As large language models continue to evolve, mechanisms like the Guardrails Orchestrator will play a vital role in making enterprise deployments more trustworthy, transparent, and safe by design.