





Some bugs in unsafe Rust arise from errors that are so easy to make that they are easily overlooked. Researchers have developed a new analyzer to find them.
By Vikram Nitin, Anne Mulhern, Baishakhi Ray, and Sanjay Arora
Rust, a programming language that did not exist just 10 years ago, is now well known and being adopted widely for a variety of projects, from static website engines to the Linux kernel. Rust is considered a safer alternative to languages like C and C++ due to its ownership model, which prevents the mutable sharing of objects. This restriction, which does not exist in C or C++, prevents a large class of programming errors. The ownership model also enables the automatic reclamation of previously allocated memory without garbage collection and without requiring the programmer to write explicit instructions for memory management.
The benefits of this language design must be paid for, in two ways. First, Rust is hard to learn and use, requiring every developer to become proficient with its lifetime annotations and associated concepts as well as its sophisticated type system. Second, sometimes the constraints imposed by Rust are simply too confining. When this is the case, the developer may take advantage of “unsafe Rust.”
Unsafe Rust is actually unsafe. Within an unsafe code region, marked by the “unsafe” keyword, many safety guarantees provided by the Rust language do not apply. Unsafe Rust resembles C far more closely than safe Rust. For example, while Rust allows pointers, just as C does, only in unsafe Rust is it permitted to dereference a pointer, that is, to read from the location pointed at by the pointer under the assumption that the pointer points to a valid memory location and that memory location contains a value of the correct type.
While it may seem that any sensible developer would eschew unsafe Rust, it turns out that unsafe Rust can be very useful in particular situations. Obvious examples include bindings for C libraries and the manipulation of pointers that may be necessary to implement a data structure. When a developer chooses to use unsafe Rust in a library, it becomes their responsibility to ensure that the library offers all the guarantees to a client that it would necessarily have if the library were written without any unsafe regions. In other words, the client should be able to use the library in the same way regardless of whether or not the library contains unsafe regions. Ensuring this can be a formidable challenge for the library developer. This is evidenced by the increasing number of reported security vulnerabilities in Rust libraries, or “crates.” In 2018, there were 26 reported vulnerabilities, but in 2021, there were 141.
This research project aims to help the Rust developer by automatically detecting errors in the implementation of unsafe regions in a Rust project.
Implementation
This project introduces the Rust analyzer and bug finder Yuga, which implements an analysis to detect and report a set of characteristic unsafety-related bugs in Rust. The analysis is a lightweight static analysis implemented as an extension of Rudra, an open source static Rust analyzer and bug finder implemented in Rust.
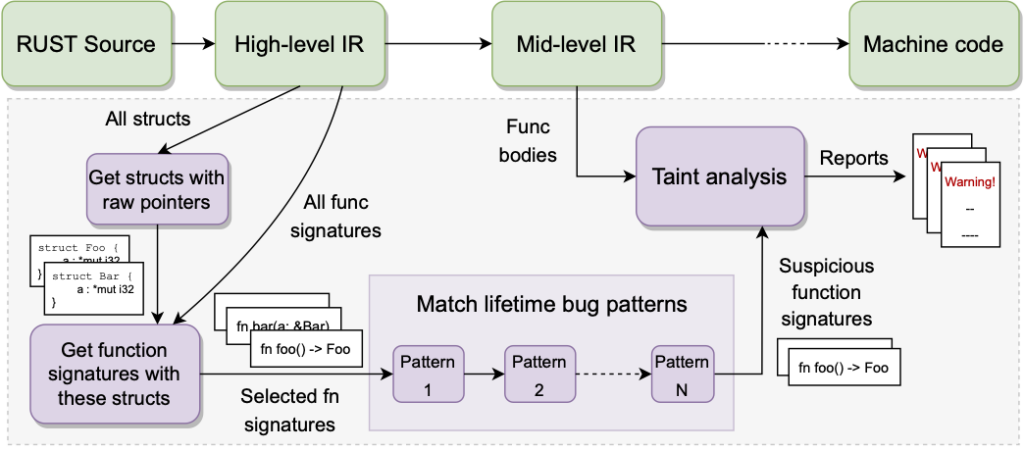
The analysis proceeds in several phases for a particular Rust crate:
- Identify all struct definitions that contain pointers.
- Identify all functions that have any of these structs in their signatures.
- Examine each function signature to determine if it contains a characteristic bug pattern.
- For any functions that contain a characteristic pattern, perform a further taint analysis on the function bodies to reduce the number of false positives.
Our tool uses two different Intermediate Representations (IRs) within the Rust compiler: the High-level IR (HIR) and the Mid-level IR (MIR). We use the HIR to get structure definitions and function signatures for steps 1-3 and the MIR to get function bodies in step 4. The entire system pipeline is shown in Figure 1.
Results and evaluation
From crates.io, the Rust package repository, we selected the top 1,600 most downloaded crates. From those, we excluded crates that would certainly fail to show any errors under our analysis, because they did not include the combination of pointers and lifetime annotations that our analysis examines.
These exclusions left us with 320 packages that might yield interesting errors. In these 320 packages, the analysis found 26 possible bugs. On examination, six of these proved real, 12 were false positives, and the remainder were a category we call “semantically safe.” Semantically safe code is code in which there is a potential bug, but it can be proved that the code can never be used in conditions that would cause the identified bug to manifest. Eliminating semantically safe bugs automatically would require reasoning about the semantics of every method in a type’s implementation.
Bug patterns
In the tradition of the FindBugs tool, Yuga inspects code looking for characteristic bug patterns.
There are three patterns that Yuga looks for:
- The Get pattern
- The Set pattern
- The Create pattern
Bug pattern example: Get
In this section, we examine the Get pattern in detail. To discuss the pattern, we must first acquaint the reader a little more with the Rust language.
First, Rust places a very strong syntactic constraint on the references that may exist to a location in memory, which may be a simple value, such as an integer, or a more complex value, such as a struct. In a single, carefully calculated contiguous region of source code, it is forbidden to have a mutable reference and any other reference, either mutable or immutable, to the same memory location.
In early versions of Rust, the contiguous region was just the scope, demarcated by matching braces. Early Rust code was, consequently, rather full of matching braces used to divide a single large region into smaller ones so that two distinct references to the same memory could exist in the separate scopes defined by the braces. These days, Rust uses a liveness analysis to determine its contiguous regions and is generally able to make them small enough so that extra braces are seldom required.
The reason for this restriction is to prevent two distinct mutators of a single memory location from interacting. This restriction:
- Prevents a large class of bugs and clears the programmer’s mind of any concerns about that class of bugs since the compiler makes them impossible
- Allows aggressive compiler optimizations so that Rust programs can be fast
A very simple infraction of this rule is shown below:
fn main() {
let mut value = 3;
let ref1 = &mut value;
let ref2 = &mut value;
*ref1 += 1;
*ref2 += 2;
}Here we have one mutable value, called “value,” and two references to that value, both of which have been declared mutable, and both of which set that value.
The compiler forbids this:
error[E0499]: cannot borrow `value` as mutable more than once at a time
--> src/main.rs:4:16
|
3 | let ref1 = &mut value;
| ---------- first mutable borrow occurs here
4 | let ref2 = &mut value;
| ^^^^^^^^^^ second mutable borrow occurs here
5 | *ref1 += 1;
| ---------- first borrow later used here
For more information about this error, try `rustc --explain E0499`.The reader is encouraged to copy this snippet of code into the Rust playground and explore variations on it, seeing which elicit a compiler error and which do not.
At first sight, and with this simple example, this prohibition may not appear terribly useful. But experienced developers will undoubtedly recall encounters with a variety of bugs that this restriction would have prevented. For example, there might be two nested loops where a reference to some struct exists in the outer loop, and a different reference to the same struct exists in the inner loop. The outer reference is overlooked, and the developer’s mistake arises from considering only the behavior of the reference in the inner loop.
Just as importantly, the Rust developer knows that once the mutable reference is found, no other mutable reference exists. This is a luxury that the Python programmer or the C programmer does not have. This simplifies debugging and even eliminates certain types of bugs, which is why Rust is gaining popularity in settings like kernel code and security-critical applications.
A developer can rely on this assurance unless there is some unsafe Rust code that destroys this guarantee. In that case, the Rust developer’s confidence is ill-founded.
To show how this can happen, we begin with a Rust struct:
struct Foo<'a> {
inner: *mut String,
#[allow(dead_code)]
extra: &'a u64, // ignore this value
}The key point here is that on the outside Foo is Rust, but internally it contains a mutable pointer to a String, as the declaration inner: *mut String shows. So far, nothing is untoward, but remember that a pointer dereference is always considered unsafe. In other words, the pre-conditions for a bug have been established.
Note that the inner field of the Foo struct is private. This means that the developer can know all the behaviors of the Foo struct just by fully understanding its associated implementation.
We add a single method to that implementation.
impl <'a> Foo<'a> {
fn get<'b>(&'b mut self) -> &'b mut String {
unsafe {&mut *(self.inner)}
}
}The parameter declaration, &'b mut self, is a shorthand for self: &'b mut Foo, that is, self has the type Foo.
We add a convenience method for creating a Foo:
fn create<'a>(bar: &'a mut String, extra: &'a u64) -> Foo<'a> {
Foo{inner: bar, extra}
}And then we demonstrate that the Rust rules work and prevent us from having two mutable references to Foo’s inner field at the same time.
fn main() {
let mut value = "Hello".to_string();
let extra = 32;
let mut foo = create(&mut value, &extra);
let ref1 = foo.get();
let ref2 = foo.get();
print!("{}, {}", ref1, ref2);
}We see the same compiler error as before: ref1 and ref2 are both mutable references to the same String, so this code is forbidden. The difference between this example and the original one is that the shared mutable reference is not to the simple integer value 3, but to the String pointed at by the inner field of the Foo struct.
However, this correctness depends on the developer getting the signature of the get() method exactly correct. There is a very natural mistake that the developer might have made. An incorrect get() method is shown below:
impl <'a> Foo<'a> {
fn get<'b>(&'_ mut self) -> &'b mut String {
unsafe {&mut *(self.inner)}
}
}The difference between the incorrect get() method and the correct one is only a single character. The method body is unchanged, and its behavior is the same. Yet with that change, the example main() method that previously would not compile does, and there are two coexisting mutable references to the same memory location.
A full explanation of why the change makes a difference is outside the scope of this article. However, the vital point is that in the correct implementation of the get() method, all the lifetime parameters, easily identified by their tick prefix, are the same parameter, 'b. Contrariwise, in the incorrect implementation of the get() method, one of the lifetime parameters is the anonymous lifetime, '_, which is different from all the other lifetime parameters in the method signature.
In the incorrect example, by including the anonymous lifetime parameter, the developer has failed to properly inform the compiler that the memory contained in a Foo struct coincides with the memory in the String that the get() function returns. Consequently, the compiler does not prevent the incorrect code in the example, and the contract between the Foo implementation and its clients is broken.
At this point, we have demonstrated that a pattern like the one above, where self’s lifetime parameter is not the same as the returned value’s lifetime parameter, may result in a bug. However, this pattern does not necessarily imply a bug. Whether or not there is a bug depends on how the body of the method is implemented.
Of the four steps of the analysis described earlier, it turns out that the first three have been completed.
1. The struct definition, Foo, has been identified as containing a pointer.
2. The get() method, which has a parameter of type Foo, has been identified.
3. The incorrect get() method has been shown to match a bug pattern.
Step 4, the taint analysis, is then run. It concludes that the incorrect get() method has been correctly identified because it determines that there is a flow from the self parameter to the result.
Both the Set and Create patterns have similar characteristics. Each pattern identifies a way in which the developer is likely to combine unsafe operations with incorrectly chosen lifetime annotations and thereby permit their code to be used so that it breaks Rust’s safety guarantees.
Conclusion
Yuga’s analysis successfully identifies bugs that other competing analyses, Rudra and MirChecker cannot. It is successful because it looks for the characteristic patterns of a particular class of bug, namely those where the developer specifies lifetime annotations incorrectly, so the compiler allows behaviors it should prevent. This can only happen in the presence of unsafe code; without unsafe code, the compiler will always be able to reject incorrect lifetime annotations.
Because it identifies likely bugs that can easily escape a developer’s notice even over a considerable period of time, Yuga’s analysis has the potential to be a practical tool for the working programmer. One drawback is that its false positive rate is inconveniently high. This false positive rate could be reduced by an analysis that was more precise than the existing taint analysis. Yuga’s analysis could also be extended to a wider variety of likely bug patterns. Currently, all Yuga’s bug patterns involve lifetime parameters, but mutability modifiers could also be considered.