



Presenting BayOp, a generic ML-enhanced controller that optimizes network application efficiency by automatically controlling performance and energy trade-offs.

As global datacenter energy use rises and energy budgets are constrained, it becomes increasingly important for operating systems (OS) to enable higher efficiency and get more work done while consuming less. Concurrently, the environmental footprint of hardware manufacturing is increasing,¹ further underscoring the importance of extracting more value from existing resources. The complexity of modern systems software and hardware and the end of Dennard scaling and Moore’s Law only add to the difficulty. Meeting these challenges will require solving the problem of how to specialize different kernel policies and hardware configurations that are often written to support only general use cases.
Moreover, as latency-critical applications, such as key-value stores (i.e., memcached), become ubiquitous across datacenters, cloud service providers more frequently choose to deploy them on dedicated hardware. Motivated by the rise of this software-hardware dedication, this article presents BayOp. This generic controller optimizes the efficiency of network applications by taming and controlling the system’s performance and energy trade-offs automatically. BayOp uses an established machine learning (ML) technique, Bayesian optimization, to exploit two hardware mechanisms that externally control interrupt coalescing and processor energy settings. The key insight behind BayOp’s dynamic adaptation is that controlling interrupt coalescing induces batching to stabilize application latency periods, making it easier to control performance-energy trade-offs and magnifying the benefits of batching with processor energy settings.
Our team of Boston University researchers and Red Hat engineers are making the following contributions toward realizing BayOp:
- We conducted a novel performance and energy study of two network applications by sweeping up to 340 static combinations of (1) a network interface controller’s (NIC) interrupt delay setting (ITR) to control interrupt coalescing and (2) the processor’s Dynamic Voltage Frequency Scaling (DVFS) to control processor energy settings.
- Our study found that performance improvements of over 74% are possible in Linux for a simple ping-pong network application by using a static ITR. We investigated the performance and energy trade-offs for a memcached server and found that tuning both ITR and DVFS can yield 76% in energy savings.
- Our data also reveal that tuning ITR and DVFS results in stable OS behavior, which implies that this structure can be captured formally. Based on these findings, we developed the BayOp controller, which can dynamically adjust the settings of a memcached server to adapt to changing offered loads and performance and energy goals while meeting different service-level agreement (SLA) objectives.
ITR performance study in NetPIPE
A common feature of modern high-speed NICs is the ability to control batching via interrupt coalescing. In this work, we explore this mechanism on an Intel 82599 10GbE by using its ITR register, which is exposed by Linux ethtool. Software typically uses the ITR register to configure a delay in 2-microsecond (µs) increments from 0 to 1024 µs. If the spacing of interrupts is less than the ITR value, the NIC will delay interrupt assertion until the ITR period has been met. Linux’s network device driver typically contains a dynamic policy that seeks to performance-tune the ITR value to better reflect the current workload.
However, our study reveals that Linux’s default dynamic ITR policy can result in performance instabilities even in a simple network ping-pong application such as NetPIPE. Figure 1 illustrates the measured performance, or Goodput, differences for a range of message sizes between Linux, which uses its dynamic ITR policy, and Linux-static, where we disabled its dynamic policy and selected a single fixed ITR value instead. This figure illustrates that using a static ITR was able to achieve higher Goodput in all message sizes. For example, at 64 KB messages, Linux-static improved its performance by 74%.
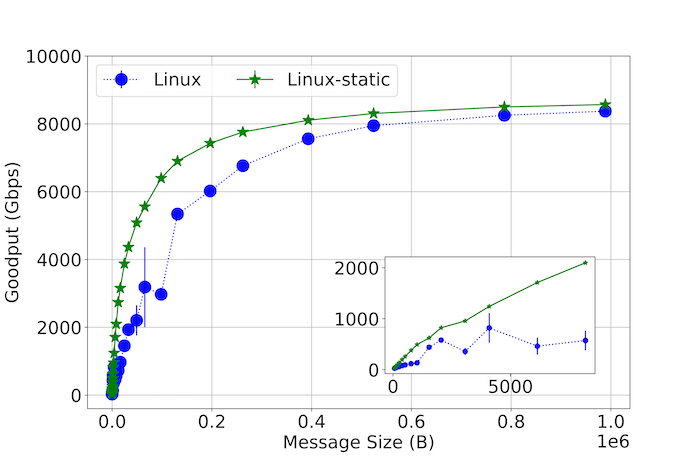
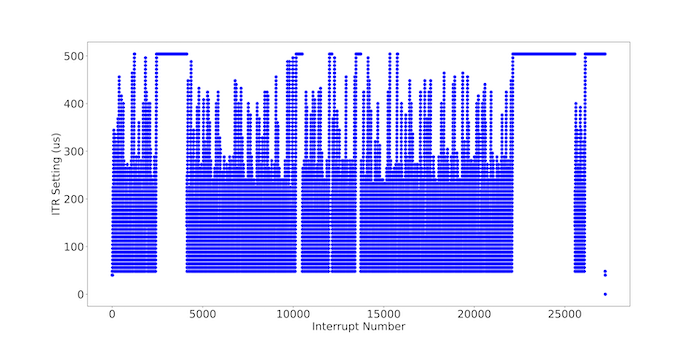
This performance difference can be traced to the behavior of Linux’s dynamic ITR policy. Figure 2 shows a snapshot of every updated ITR value captured in Linux’s network device driver during a single run of NetPIPE using 64 KB message sizes. This figure illustrates the extreme variability (up to 500 µs) at which ITR is updated on a per-interrupt basis. This variability suggests that the current dynamic policy, designed to support general use cases, is operating at the wrong timescale for an application such as NetPIPE and that further specialization can yield significant advantages.
Performance and energy
We then expanded our study to uncover the performance and energy trade-offs within this space. Toward this end, we explored the novel use of ITR and DVFS by statically configuring up to 340 unique combinations of each across both NetPIPE and a memcached server. In Figure 3 and Figure 4, we compare Linux-static, which statically sets both, against Linux, which uses the dynamic ITR policy and dynamic DVFS powersave governor. Memcached is an example of an application with an external request rate that can largely be considered independent from the time required to service a request. Service providers often set an SLA target for these types of applications, such as some percentage of requests to be completed under a stringent time budget (99% tail latency < 500 µs for Figure 4). At the same time, there is a constant stream of requests-per-second (QPS) arriving at the server.
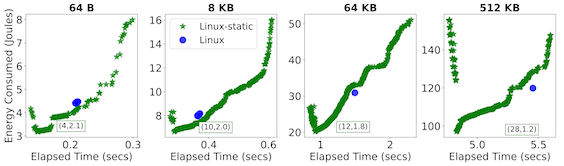
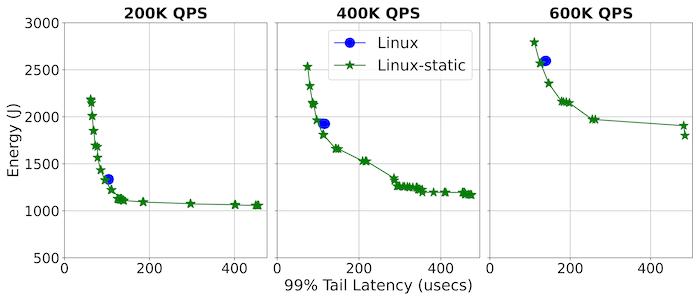
Figures 3 and 4 illustrate a rich performance and trade-off space between Linux and Linux-static, whereby tuning both ITR and DVFS can result in dramatic energy savings of over 50% and even improve performance in the case of NetPIPE. This study also reveals characteristic shapes of Linux that differ depending on the application. For NetPIPE, there is the V shape. The lowest point in this V shape represents a setting that uses the lowest energy while being competitive in performance; the vertical points above represent other configurations that sacrifice energy for better performance. Note that Linux always lies to the right of the V curve, indicating the value of doing such a static search. In contrast, memcached reveals an L shape. While this L shape differs in absolute performance and energy, the underlying Linux response to changes in (ITR, DVFS) combinations remains stable across the offered loads, which suggests one can capture these behaviors formally.
BayOp design and results
To operationalize these energy savings and stabilize OS response behaviors, we built BayOp, an application- and OS-agnostic controller using a sample-efficient ML technique—Bayesian optimization—to automatically probe for efficient (ITR, DVFS) settings within a running system while under changing offered loads. In particular, we targeted applications such as memcached, where the SLA space enables a rich set of performance and energy trade-offs.
We used BayOp to automatically tune a memcached server while servicing a publicly available memcached trace from Twitter. Twitter’s trace reveals that these services often maintain a mean demand curve that changes slowly over periods of 24 hours or more. These can be attributed to either diurnal access patterns or can be induced through service admission control layers such as load balancers. These curves suggest that specialization of a single application at a specific offered load can be a realistic form of optimization to exploit the stable regions of these demand curves.
Figure 5 illustrates the BayOp controller design. In phase 1, a live system running memcached is currently servicing various QPSes from an external source. BayOp will then periodically trigger a set of performance and energy measurements of the live system in phase 3. For each measurement in phase 3, the Bayesian optimization process is used to compute a reward penalty of its current configuration and then, in phase 4, recommend and update a new (ITR, DVFS) pair on the live system such that it minimizes the reward penalty. Once this process is finished, the memcached server is set with a static (ITR, DVFS) setting until the next set of measurements is triggered.
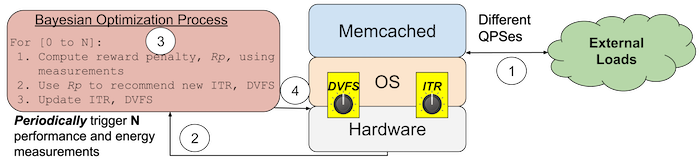
Figure 6 illustrates results from two different SLA objectives: 99% latency < 500 μs, and a stringent 99% latency < 200 μs. The figures to the left illustrate the system’s energy usage on a per-second basis over a 24-hour period, and the change in hourly QPS rate is also indicated. At the beginning of each hourly QPS rate, there are spikes in energy usage from Linux-BayOp, the result of the Bayesian optimization process as it dynamically searches through (ITR, DVFS) settings on the memcached server to meet its corresponding SLA objective. After this initial energy spike, the system settles to a steady energy consumption state until the next hourly trigger. The figures to the right illustrate the latency trade-offs BayOp makes to maintain SLA objectives while saving energy.
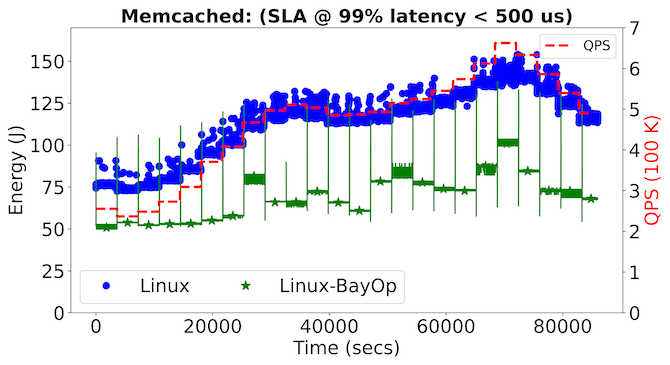
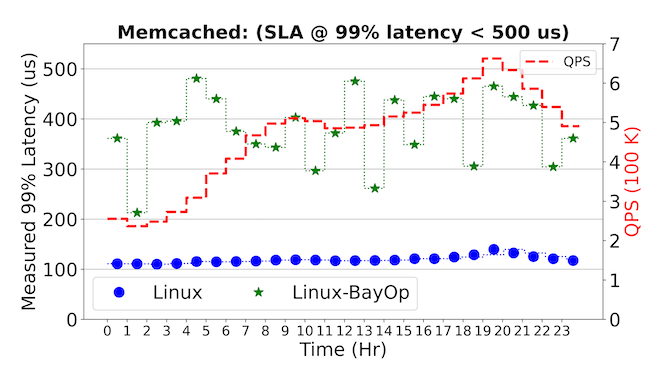
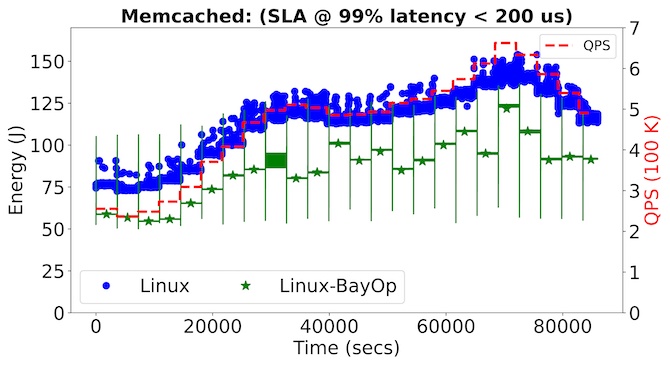
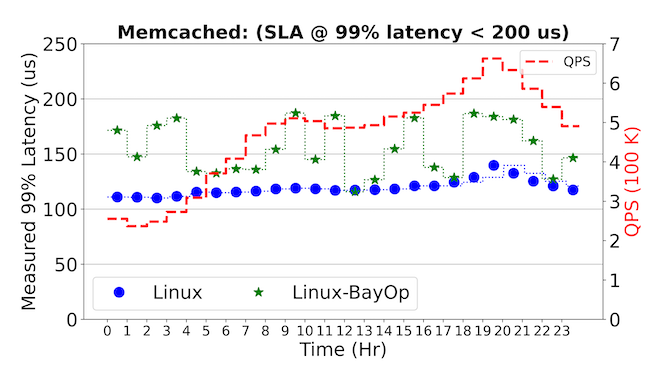
Figure 6. BayOp applied to cache-trace QPS rates over a 24-hour period for memcached. Each row represents a different SLA objective and shows the measured energy per-second as QPS changes across the five system configurations studied.
In the case of an SLA objective of 99% latency < 500 µs, we find that Linux-BayOp can result in energy savings of up to 50% over Linux. Even at a more stringent SLA of 99% latency < 200 µs, Figure 6 shows that Bayesian optimization can adapt to this new requirement while saving up to 30% energy. These results demonstrate the generality of the BayOp controller. They also reveal the limitations of Linux’s existing dynamic policies, as one cannot use its current ITR and DVFS algorithms to express these rich performance and energy SLA trade-offs.
Future directions for BayOp
BayOp’s design as an external controller creates the potential to integrate with load balancers to exploit and optimize a dynamic fleet of servers that direct incoming offered loads to one or more servers configured with specific ITR and DVFS. Additionally, if servers are added or removed from the fleet, BayOp re-optimization can then be coordinated with re-balancing.
In our use of BayOp to optimize memcached servers, we make certain simplifying assumptions, such as the hourly trigger to run the Bayesian optimization process. While we have demonstrated that these simple assumptions can result in significant advantages, there is considerable room for improvement. BayOp’s architecture enables the integration of more advanced policies for deciding when to trigger the Bayesian process, such as in response to dramatic changes in QPS rates or exploiting historical patterns in service loads. The Bayesian optimization package can also be improved to reduce the cost of sampling.
Our work is currently being extended through the Red Hat Collaboratory at Boston University to improve performance and energy efficiency for open sourced stream processing applications as well. Reach out to handong@bu.edu with questions, see the data collection infrastructure at GitHub, or visit the project page on the Red Hat Research website.
Footnote
1. “Chasing carbon: the elusive environmental footprint of computing,” IEEE International Symposium on High-Performance Computer Architecture (HPCA 2021).