








")
Simplify scheduling with an intelligent, multicluster-aware scheduler capable of automatically handling dependent Kubernetes resources and ensuring network connectivity between distributed services.
Scheduling resources across a multicluster environment is not a trivial task. As part of a recent cloud-to-edge research collaboration, P2CODE, a team of engineers based out of Red Hat’s Waterford office in Ireland took on the development of a scheduler designed to address this challenge, allowing developers to provide generalized descriptions of the conditions under which the application should run without being subject to the intricacies of the infrastructure layer. P2CODE, an EU Horizon-backed initiative, aims to create a cloud-native programming platform that simplifies the development and deployment of applications that can be distributed across cloud or private edge environments or sent to a diverse range of IoT devices. In the creation of this scheduler, we drew inspiration from both Red Hat’s Advanced Cluster Management (ACM) and the MultiClusterNetwork operator developed as part of another EU-funded cloud-to-edge research project, AC3 (Agile and Cognitive Cloud-edge Continuum management).
Overview
The scheduler needed to be platform agnostic, as the various academic and industry partners in the P2CODE consortium brought one or several clusters. The ability to partition and logically divide the clusters was important to enable isolating one partner’s workloads from another. Furthermore, considering the infrastructure topology, we wanted to be able to target a given cluster via the scheduler. Red Hat’s Advanced Cluster Management provides much of this functionality and hence serves as the foundation of the scheduler.
Moreover, ACM provides the resources necessary to delegate workloads to a specific cluster or to identify a cluster that matches the user’s criteria using highly expressive Placement rules. However, Placement resources can become quite verbose when a user has more fine-grained requirements. To overcome this, we designed an abstraction layer on top of the Placement API offering application developers a simplified, annotation-based mechanism to describe workload requirements.
While this approach improves flexibility, the longer term aim is to provide a standard set of annotations that can be used to target workloads. The standard set of scheduling annotations can be used more broadly with other multicluster scheduling frameworks, such as Karmada, providing developers and cluster administrators with a truly flexible framework for deploying applications.
Historically, when a developer wanted to deploy a workload to a certain cluster, they would be responsible for grouping together the workload and all dependent resources and sending them to the same cluster. Intelligent logic was added to the scheduler to automatically bundle a workload and its ancillary resources and deploy the resources to the chosen cluster, easing the burden on developers.
When working in a multicluster environment, developers also need to perform additional manual checks to confirm connectivity between cooperating workloads scheduled on separate clusters. To address this need, the MultiClusterNetwork resource was integrated into the scheduler. This enhances the scheduler with the ability to establish communication between microservices running on separate clusters.
Scheduler deep dive
The scheduler is in fact a Kubernetes operator that leverages the ACM framework, as shown in Figure 1. It runs on the hub cluster where the ACM operator is installed and is authorized to interact with the managed clusters under the control of the hub cluster. Users can define their workloads and scheduling requirements via the P2CodeSchedulingManifest custom resource. Scheduling requirements are specified as key-value pairs, which translate to ClusterClaims, essentially labels in ACM used to highlight features of the managed cluster. ClusterClaims provide the flexibility to define any property of interest to developers. Cluster administrators are encouraged to apply ClusterClaims to distinguish the managed clusters.
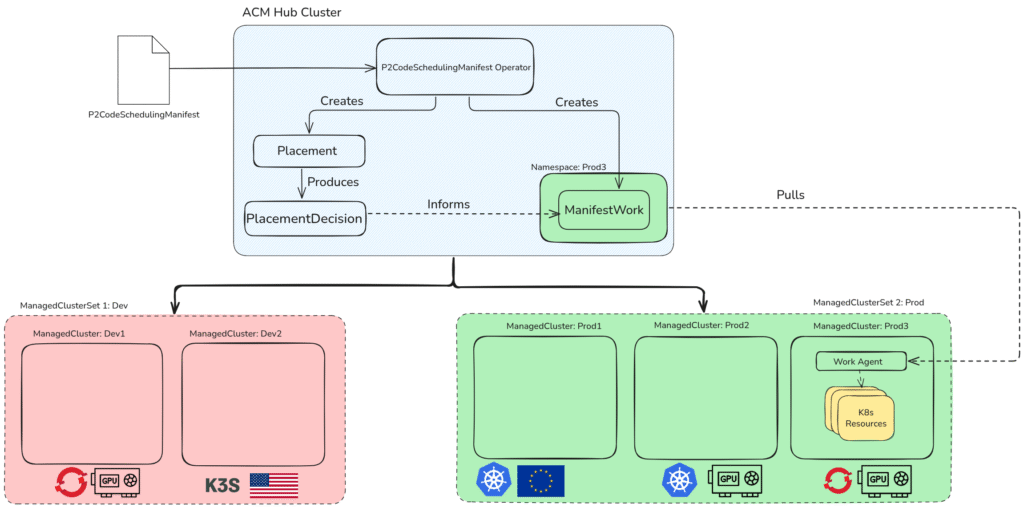
For example, a ClusterClaim could describe the region the cluster is hosted in, the Kubernetes distribution installed (e.g., K8s, OpenShift, K3s), or the owner or purpose of the cluster. A ClusterClaim can also describe the hardware available on the cluster, if it runs on renewable energy, or if it has special security features. With the ClusterClaims defined, one final configuration step must be carried out by cluster administrators. When using the scheduler, developers must specify a cluster set to use. The global cluster set exists by default and includes all managed clusters under the hub’s control. It is preferable for the cluster administrator to provision additional cluster sets and distribute the managed clusters across these. For example, there could be a cluster set for development, testing, and production.
A developer must create a P2CodeSchedulingManifest to use the multicluster environment configured by the cluster administrator. To do so, a list of resources to be deployed is given under the Manifests field of the P2CodeSchedulingManifest. The list of manifests is akin to a helm chart detailing all the components required for an application to run. Developers can provide additional scheduling requirements at the global or workload level. An annotation specified at the global level is applied to all manifests and takes precedence over any workload annotations. The target managed cluster set annotation is mandatory and defined at the global level. Optional workload annotations offer developers more fine-grained control over the scheduling of components. Developers can define a mixture of global and workload annotations in the P2CodeSchedulingManifest. For example, a developer may want all their components to run on an OpenShift cluster, while one AI workload must be scheduled to a cluster with a GPU.
Upon deploying the P2CodeSchedulingManifest resource, the scheduler uses the scheduling requirements to create ACM Placement resources. The placement returns a suitable cluster that forms part of the ManifestWork, which is used to define what resources should be present on a particular managed cluster. Essentially, the scheduler combines the multistep process of selecting a cluster and deploying to the chosen cluster. It also performs intelligent bundling to populate the ManifestWork with the specified workload and any ancillary resources, such as secrets, config maps, services, routes, persistent volume claims, or role bindings required for the workload to run as expected. With all the workloads bundled and the ManifestWorks prepared, the scheduler applies the ManifestWorks, sending the workloads to the user defined location.
One of the core benefits of the scheduler is a reduction of the developer’s workload. Under the hood, the scheduler creates the necessary ACM resources and interprets the results to either provision additional resources or reflect the state of the deployed resources. The automatic bundling feature further alleviates work for the developer, as they don’t need to tag the location of each and every resource. For example, in Figure 2, the developer specifies that their httpd server should run on a Kubernetes cluster while their nginx server should be hosted on an OpenShift cluster. For the nginx server to operate as expected, the config map with the name server-config must also be located on the same OpenShift cluster. The scheduler automatically bundles these resources together, reducing work for the developer.
The first version of the scheduler blindly accepted and fulfilled scheduling requests without considering the interdependency of components. Imagine that the frontend and backend of an application get sent to different clusters. Frontend calls to the Kubernetes backend service no longer succeed, as the application cannot natively communicate with a Kubernetes service located in a different cluster. Fortunately, the network operator developed in the EU Horizon-supported AC3 project was designed to overcome this exact issue. The scheduler analyzes the K8s services within the P2CodeSchedulingManifest, bundling the service with the workload it exposes. Separately, it examines each workload for environment variables that reference K8s services. If that service is contained within a bundle destined for a different cluster than that of the bundle with the calling workload, the scheduler flags it and creates a MultiClusterNetwork resource that is handled by its operator. This is where the collaboration between the P2CODE and AC3 project began.
MultiClusterNetwork Operator
The network operator
The AC3 project aims to provide a sustainable, AI-managed, platform-agnostic, federated cloud-edge infrastructure for deploying and scaling applications while optimizing resource efficiency and network performance. (See a specific use case for AC3 in “Concurrent, scalable, and distributed astronomy processing in the AC3 framework,” also in the Winter 2025-2026 issue.) The MultiClusterNetwork operator eliminates the complexity of manually configuring cross-cluster calls through declarative networking. Instead of managing network infrastructure, platform teams simply describe their desired service relationships in Kubernetes YAML. The operator handles establishing secure tunnels, managing service discovery, and ensuring seamless traffic flow between any number of clusters through simple declarative configuration.
The MultiClusterNetwork operator takes a technology-agnostic approach to multicluster connectivity, abstracting away the underlying networking implementation details. By encapsulating networking complexity behind intuitive, business-focused custom resources, it transforms multicluster networking from an infrastructure challenge into a simple YAML declaration. This technology-agnostic design allows platform teams to focus on application architecture rather than network plumbing, providing flexibility to evolve networking strategies without changing application definitions.
Architecture and workflow
The architecture diagram illustrates the MultiClusterNetwork operator’s hub-and-spoke design, where a centralized control plane cluster manages networking across multiple distributed datacenter clusters. At the heart of this architecture lies the Network Controller, which serves as the core orchestration engine processing network definitions and coordinating cross-cluster connectivity through a Northbound API that allows users to define multicluster network requirements via Kubernetes custom resources.
The system’s technology-agnostic approach is demonstrated through its plugin architecture, supporting multiple networking implementations including Skupper, Submariner, and SD-WAN solutions through interchangeable components. This design flexibility ensures organizations can evolve their networking strategies without rebuilding application connectivity definitions.
The operational workflow, as shown in Figure 3, centers on two critical processes: creating secure network connections between specified application namespaces across target clusters, and managing authentication token distribution for secure cluster-to-cluster communication. The orange tunnels between Data Centre 1 and Data Centre 2 represent these encrypted connections, enabling applications in different namespaces across geographically distributed clusters to communicate as if they were local services.
Adapting to real-world complexity
One of the biggest challenges in multicluster networking is that not all services are created equal. A simple web service might need different handling than a complex database cluster or a legacy application that was containerized but still has special requirements. The MultiClusterNetwork operator was designed to handle these cases intelligently and inspect each service to understand its deployment context and apply the appropriate networking strategy. This means platform teams can offer a single, consistent interface for multicluster networking while still handling the diverse needs of different applications.
Key takeaways
The intelligent multicluster scheduler developed provides a complete solution for managing distributed applications. The P2CodeSchedulingManifest acts as a unified interface for scheduling and deploying applications with the additional guarantee of network connectivity between components. The P2CodeSchedulingManifest resource offers the right level of abstraction to be useful in simplifying multicluster scheduling without compromising on flexibility. The dynamic scheduling annotation mechanism is central to the scheduler.
Developers can easily specify scheduling requirements and update them as needed as further requirements are discovered. In particular, as workloads move from development to testing to production, the scheduler can match the workloads to a suitable cluster within the selected environment with ease. The intelligent multicluster scheduler has made significant improvements in streamlining the process of both selecting and scheduling in a multicluster environment. To learn more, view the P2CODE scheduler repo with support for MultiClusterNetwork resource or the MultiClusterNetwork operator repo on GitHub.
Acknowledgements

P2Code is funded by the European Union under Grant Agreement No. 101093069. Views and opinions expressed are however those of the author(s) only and do not necessarily reflect those of the European Union or European Research Executive Agency. Neither the European Union nor the granting authority can be held responsible for them.