








Improvements to the research-developed tool for analyzing unsafe Rust have rendered it much more precise.
Yuga is a static software analysis tool for identifying lifetime annotation code defects in Rust code. At the time it was first presented in a previous article in the Red Hat Research Quarterly, Yuga’s analysis yielded an unacceptably high number of false positives in the experiments conducted. Since then, the analysis has been refined. Yuga is able to detect code defects that are not detected by competing tools, and the precision and recall of its analysis are much improved.1
Static analysis tools
Just about every software developer these days makes use of some static analysis tool. (A static analysis is an analysis that is done solely by inspecting a program’s source and never by actually running the program.)
I suppose that the first static analysis tool invented was a type checker. Like all type checkers after it, it occasionally rejected correct programs; that is, it was incomplete, because its static analysis could not determine the correctness of all correct programs. It was supposed to be sound, however; in other words, it would reject any program that could encounter a type error. Incompleteness is a mathematical necessity for the type checker of any but the simplest language, but unsoundness in a type checker is a bug.
We can put these properties of soundness and completeness in terms of precision and recall if we think of the type checker as simply a finder of a certain class of code defects: those that can result in type errors. Recall is the ratio of true positives to all code defects in a program. Since the type checker is required to be sound, it must find all the defects, so that number is the maximum possible value, 1. Precision is the ratio of true positives to all code defects identified by the type checker. Since the type checker is incomplete, that value is less than 1: it identifies more code defects than there actually are.
Type checkers are not the only static analysis tool. Many static analysis algorithms for many languages exist. Most are not part of the compiler, but many make use of compiler infrastructure to provide data for their analyses. Most do not guarantee that either precision or recall is 1, and generally neither is. Recall can be maximized by a strategy of declaring that there are errors everywhere, but this strategy comes at the expense of precision.
In general, a good static analysis tool should have high recall: in any given program it should find most of the kind of code defects that it is designed to find. It should also have high precision: it should not identify many errors incorrectly. If a static analysis tool has low precision, a developer may spend a lot of time examining code that is not actually defective. If a static analysis tool has low recall, the code defects will persist in the program and, sooner or later, this will result in bug reports, unless the developer finds the problem by other means.
It is the nature of LLM-based tools that their analysis is indiscriminate.
Recently, code review tools that use large language models (LLMs) to check proposed code changes for code defects have become available. In principle, recall and precision metrics for these tools could be obtained. However, unlike traditional static analysis tools, these LLM-based tools are non-deterministic. Typically, a traditional static analysis tool, for example Rust’s Clippy, consists of many separate analyses that run independently and can be turned on or off as desired. Given a dataset, recall and precision values for any particular analysis can be calculated. It is the nature of LLM-based tools that their analysis is indiscriminate; they do not check for anything, they just respond. The recall and precision values will vary, even for the same dataset.
Rust
The Rust language has a flexible and expressive type system. Its type checker is conditionally sound and incomplete. There are certain Rust functions, explicitly labeled unsafe (e.g., std::mem::transmute), that allow the developer to change the type of a region of memory. If the user uses these functions in a correct way, the type checker is sound; otherwise it is not. Due to the flexibility of its type system, the Rust type checker’s precision is higher than that of many other languages. Its recall value is 1 if the developer does not make incorrect use of unsafe functions that affect types.
The compiler also provides an ownership checker. This tool identifies a different kind of code defect and prevents a different kind of bug than the type checker. The bugs that the ownership checker must prevent are memory-related bugs.
Unlike, for example, Java, Rust has no garbage collection; unlike C, it does not rely on explicit memory management. Instead, it avoids common problems, like use-after-free, that plague C programs by enforcing its ownership rules. Every region of memory being used by a Rust program has just one owner. After that owner is no longer live, but never before, the region can be freed. It is the job of the compiler to emit code that will free the memory once it is unused, so that it can be reused. This must be done perfectly, in order to avoid “memory leaks.”
Although a region of memory may have only one owner, there can be many borrowers. These borrowers can also access the region of memory. It is vital that no borrower access memory after the owner has ceased to be live; if it ever does that, the memory may have already been freed and reused for another purpose during program execution. If that happens, the reference will read a garbage value, which will result in undefined behavior. So, there are rules that ensure that no borrower can be live after the owner has ceased to be live. The Rust borrow checker exists to enforce these rules.
If the developer adds certain lifetime annotations incorrectly, the borrow checker may allow a memory violation.
To enforce its rule that borrowers must not live longer than the owner of a region of memory, the borrow checker has a concept of lifetimes. It uses sophisticated analyses to determine whether the lifetime of a reference to some region of memory may extend beyond the lifetime of the owner. Since that could result in undefined behavior, its job is to prevent this from happening.
The Rust compiler can infer a large proportion of lifetimes without assistance, just as it can infer most types in a program. In some cases, however, the developer must use lifetime annotations to inform the compiler what lifetimes it should assume. This is something the developer can get wrong, and the consequences of an error can be a memory safety bug. Like the type checker, the borrow checker is only conditionally sound. If the developer is able to add all the lifetime annotations correctly, the borrow checker will not allow any of the memory-safety violations it is designed to prevent. But if the developer adds certain lifetime annotations incorrectly, the borrow checker may allow a memory violation.
Few developers, when they first encounter Rust, have experience developing in a language that enforces ownership rules. The errors from the borrow checker are rather confusing. Sometimes it is quite a struggle just to get the program to compile. The likelihood that a novice or even an experienced developer will fall into an error when adding lifetime annotations is high.
Yuga
Yuga is a static analysis tool to detect code defects that arise due to incorrect lifetime annotations inserted by a developer.
Incorrect lifetime annotations
Figure 1 shows a complete and buggy program where lifetime annotations have been inserted incorrectly.

Figure 2 shows one possible outcome of running the program. obj.x is supposed to point at the string “Hello2”, but when the program prints out the value at obj.x, it is the string “Goodby”. What happened is that v2 owned the memory containing the string “Hello2”. Because of the incorrect lifetime annotation on the function bar(), the borrow checker was unable to detect the code defect in main(), and the compiler calculated that v2 had no live borrowers after the invocation of bar(). Hence the invocation of drop(), which consumed v2 and caused the release of the memory on the heap belonging to v2, was allowed by the borrow checker.

Invoking the drop() function resulted in the memory on the heap containing “Hello2” being released and then immediately reused for the string “Goodbye To All That”. But the pointer at obj.x, the invisible to the compiler borrow of v2, remained. So when the string pointed to by obj.x was printed out, it was “Goodby”, the first six characters of “Goodbye To All That”, rather than “Hello2” as one would have expected just from looking at the source of main().
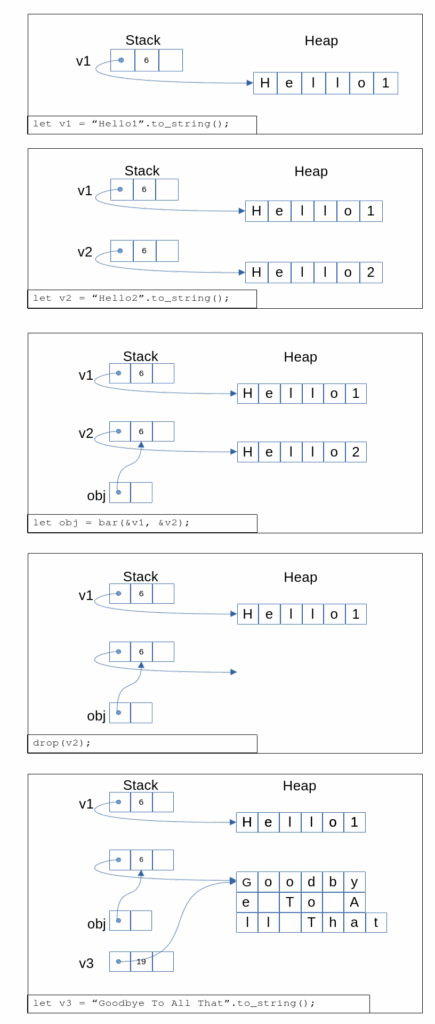
Several things make this example even more complex than it would otherwise be. First, while the bug could happen without the call to the drop() method, it likely will not. The borrow checker allows the drop() invocation at that point, because v2 is unused after that point, and it is not aware of the invisible borrow through the pointer. It would not allow a drop() invocation immediately after the assignment to v2 and before the invocation of bar() because v2 is still live at that point, since it must be passed as an argument to bar().
Second, v2’s header is kept on the stack, not the heap. v2’s header, like the headers of all Strings, contains a pointer to an object on the heap that holds the characters in the string, a field indicating the size of the string, and another field irrelevant to this problem. obj.x points at the header on the stack.
Third, all that we have described so far would not have resulted in a bug without obj.x being dereferenced. Any dereference of a pointer is considered unsafe, and it must always be designated unsafe. Here, the dereference is inside an unsafe block in main(). This kind of complex reasoning is usually required with lifetime annotation bugs.
What made this bug possible was a mistake in the declaration of the function bar(). Specifically bar()’s return type is Foo<’a>, but it should be Foo<’b>. The type, Foo, is correct, but the wrong lifetime annotation was selected, and the return value’s lifetime is connected to the lifetime of arg1, not of arg2. As far as the borrow checker can tell, there is nothing about bar() that requires the second parameter, arg2, to live past the print statement in bar() itself. Thus it concludes that v2’s lifetime ends with the invocation of bar().
How could the borrow checker analyze that simple function and fail to identify the incorrect lifetime annotation? The type of x is that of a pointer to a String. The borrow checker simply ignores pointers when doing its analysis, because they are really just values, or addresses in memory. For this reason, the prudent Rust developer will avoid using pointers unless necessary. Sometimes it is absolutely necessary; Yuga could help the Rust developer go wrong less often in that case.
How does Yuga work?
Recall that the borrow checker ignores pointers when performing its analysis. Yuga’s foundational principle is to pretend that the pointers are references of the kind that the borrow checker does not ignore and to analyze the code with pointers as if the pointers were references. One rule the borrow checker uses is that if a struct contains a field that is a reference, then that field must outlive the struct that contains it. Yuga will conceptualize a pointer in a struct as if it were a reference and deduce the same rule for a pointer in its analysis, that it has an outlives relationship with its struct. Then Yuga will examine functions, using a type-based algorithm to match argument types with return types.
For the code example in Figure 1, Yuga can discover that it is possible that one of the parameters of bar() could end up in the returned value of Foo, simply because a value of type *String can be constructed from a reference to a String. Thus, just reasoning by types, arg1 or arg2 could end up in the return value; therefore Yuga reasons that to be safe, both should have lifetimes that exceed that of the return value. The borrow checker will only ensure that holds for arg1, since Foo’s lifetime parameter is the same as that of arg1. Therefore, if arg2’s value becomes part of the Foo return value, there is a bug.
Such a simple, type-based approach is bound to yield far too many possibly buggy functions that are not actually buggy. It is a high-recall, low-precision analysis that would seriously waste a programmer’s time. Yuga refines the analysis and improves its precision by a points-to analysis on individual function bodies. The points-to analysis increases the precision, but does not reduce the recall. Yuga has experimented with several additional ways of reducing the number of false positives, with some success.
Results
Yuga’s performance was tested under several scenarios. First, it was tested against a well-known set of Rust lifetime annotation bugs in nine crates identified by searching the Rust Security Advisory database (rustsec.org). Second, a dataset of synthetic bugs was prepared. And finally, Yuga was run on a dataset of 375 crates on crates.io. These crates were selected from the top 2,000 crates. Crates that did not use unsafe code or lifetime annotations were removed, leaving just 375 popular crates that might have lifetime-annotation bugs. Yuga found three completely new bugs, as well as many instances of suspicious code.
Three new bugs may seem like just a few, but it is important to remember that these bugs were in crates that see a lot of use and, hopefully, get a lot of scrutiny. Less well used and examined crates would be likely to contain a greater proportion of such bugs
Conclusion
Yuga is a research prototype, not a production-ready tool. Yuga searches only for one kind of very difficult-to-reason-about code defect which other bug finders generally do not detect at all. We should not overlook the benefit of novelty in a bug-finding tool. By using a tool that reports a kind of defect other tools can not detect, the developer learns to understand this kind of defect and to avoid it in future, even if the tool is not always available. Most developers will put up with a high rate of false positives, so long as they are learning something new and permanently useful. That is largely the appeal of the LLM-based code review tools at this time.
Footnote
- “Yuga: Automatically detecting lifetime annotation bugs in the Rust language,” Vikram Nitin (Columbia University), Anne Mulhern (Red Hat Research), Sanjay Arora (Red Hat Research), Baishakhi Ray (Columbia University). In (2025) ACM International Conference on the Foundations of Software Engineering (FSE) (Trondheim, Norway); (2024) IEEE Transactions on Software Engineering 50(10), pp. 2602-13. ↩︎