
")


Is there a way to implement load balancing in multicluster environments that won’t increase resource usage? New research suggests the answer is yes.
Multicloud providers and microservice-based applications across clouds are becoming increasingly popular. Organizations that use them enjoy the benefits of high availability, performance improvements, and cost effectiveness.
However, as microservices communicate with each other over a network, the deployment of microservices-based applications in multiple clouds runs the risk of increasing the application execution time, traffic cost, and more. For example, two dependent services tend to communicate frequently. Allocating them on different clouds leads to high cost and high delay.
While working on my thesis with Prof. Anat Bremler-Barr from Riechman University and Prof. David Hay from the Hebrew University, we were contacted by Red Hat Research team lead Idan Levi and engineer Livnat Peer. They introduced us to an interesting problem: how to optimize the service selection mechanism given a certain service distribution among multicluster and multicloud deployments. The load-balancing approaches used thus far have not been adequate for a multicluster environment for several reasons, explained below.
Our research suggests a new approach for addressing the problem. We have introduced a new system called KOSS (Kubernetes Optimized Service Selection), which optimizes service selection specifically for Kubernetes. KOSS utilizes Submariner (submariner.io), which is used to connect Kubernetes clusters networking layer (across geolocations and cloud providers), forming what is called a multicluster or a cluster set. Submariner forms a full L3 network mesh connection in Kubernetes multicluster environments, using encrypted VPN tunnels, and allows cross-cluster service discovery.
The service selection problem
Prof. Bremler-Barr, Prof. Hay, and I defined the following service selection problem and model. When optimizing the communication load between microservices, there are two types of communication layouts to be considered: the inner-cluster (i.e., between services in the same cluster) and the inter-cluster (i.e., between microservices located in different clusters). We focus on the inter-cluster layout and offer a solution for the optimization problem derived from it. For each layout, the system must attend to two main questions.
One: How and where to implement the load balancing
Traditionally, there are three load-balancing architectures:
Instance-oriented, where a central load balancer is aware of all the service instances and balances the load between them. While this approach can balance loads across instances well, it introduces price and performance overhead when communicating between the load balancer and the instances.
We suggest a new approach: cluster-oriented, where the selection decision is made in a centralized component and yields policies that are updated and distributed at each cluster for local and efficient routing.
Microservice-oriented, where services of the same type are grouped together and assigned a load balancer that directs the traffic between the instances of the same type. While this approach may alleviate the overhead introduced in the instance-oriented approach when applied within the same cluster, it does not take into account service-to-service interdependency, and it will introduce communication overhead when used in a multicluster environment.
Client-oriented, where the client itself uses a load balancer (client here refers to an instance of a microservice). The load balancer is usually implemented as a sidecar application that shares namespaces and resources with the application container and acts as a proxy for the requests. This approach is widely used in the industry and adopted by all service mesh solutions. The approach offers resilience and fine-grained control for balancing the load in the system. However, it introduces two additional hops between the instance and the sidecar application. In addition, the sidecar application requires extra resources for operation and propagation of the policies.
We suggest a new approach: cluster-oriented, where the selection decision is made in a centralized component and yields policies that are updated and distributed at each cluster for local and efficient routing.
Two: How to optimize the service selection
Optimization-wise, there are two main concerns:
Optimization parameters: latency, pricing, congestion, response time, etc.
System constraints: capacity, load, special topology knowledge (such as one-hop, where the model optimizes only one hop between two services, as in Figure 1, and chain-based, where the full dependency graph of the application is taken into account), etc.
The service selection optimization problem lies at the heart of our system. Our system and the corresponding optimization problem are working in a hop-by-hop manner, where only the next-hop destination of each request is considered for service selection. Nevertheless, we handle the interdependence of services over every single hop and accommodate competition between the different services, as shown in Figure 1.

We summarize the notation we use in Table I. We define the following optimization problem:
(1)
(2)
(3)
(4)
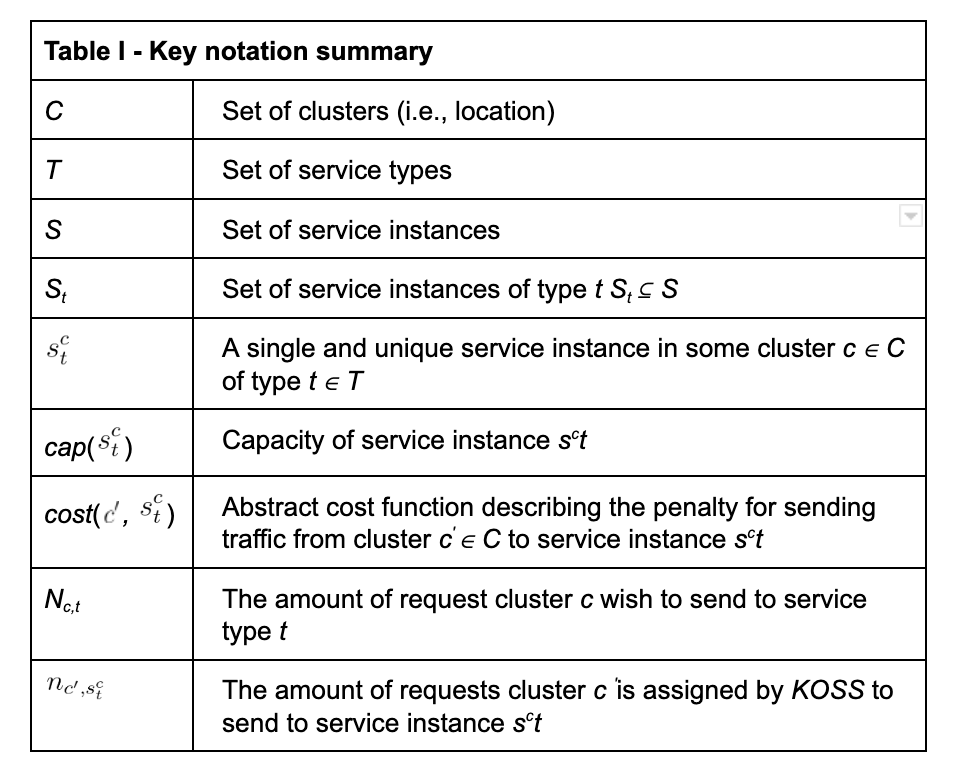
The optimization problem (1) aims to minimize the cost of sending requests within the system, while (2) prevents requests from being dropped, (3) avoids suppressing the instance capacity, and (4) allows minimal traffic per service instance. We defined an integer linear programming (ILP) optimization and solved it. With the solution—that is, the assignment for each variable the optimization problem will yield—we calculate a weight for each specific cluster to service instance relations as follows:
(5)
Because we use weighted-round-robin load balancing, which supports floats, we allow the relaxation of the constraints and treat the variable as continuous.
KOSS system design
While working on the implementation of the KOSS system, I had great help in designing the system and implementing it from the Submariner and multicluster development team, including Vishal Thapar, Mike Kolesnik, Tom Pantelis, Sridhar Gaddam, Miguel Angel Ajo, Stephen Kitt, and others, led by Nir Yechiel. Our cluster-oriented approach, which separates the control and data planes and allows efficient updates while supporting fine-grained control over the load balancing, is described in Figure 2. KOSS seamlessly uses Submariner control-plane components and forms its own distributed control-plane (the Broker) and data-plane (Lighthouse DNS plugin) layers. In a nutshell, the broker, which has a global view of the system, solves the optimization problem and distributes its outcome to other clusters. The Lighthouse plugin, a DNS service discovery, makes efficient and independent routing decisions while collecting metrics at each cluster.
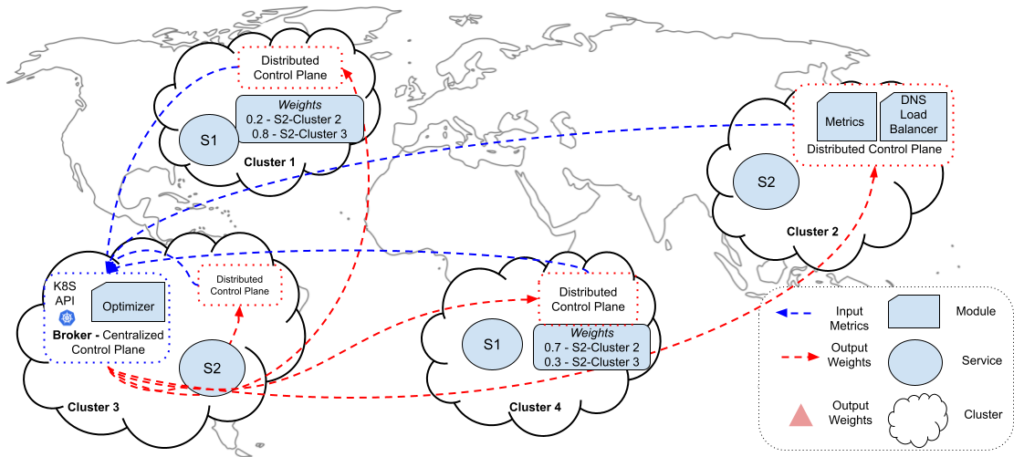
Figure 2: KOSS implementation over Submariner control plane. A centralized broker running optimization and decentralized Lighthouse plugin runs metrics collection and load balancing at each cluster.
Experiments and evaluation
In the evaluation, we take into account two metrics for the cost function:
Price, which we define as the egress traffic price per GB of data
Latency, which we define as the ping latency between two clusters, measured in milliseconds
We specifically chose to optimize latency and pricing because these two parameters are crucial for most operators and easy to measure. We use the weighted sum technique to normalize the chosen parameters for the cost function and support the multi-objective optimization.
(6)
For example, when optimizing requests sent from cluster c1 to service type t (which has instances deployed in cluster c2 and c3 ), we decided to allow the same importance for both the price and the latency parameters. Hence, we defined β = 0.5.
Experiments
We conducted numerous experiments and simulations, and the simulator and dashboard we have built are available online for everyone to use. We outperformed the current round-robin implementation and avoided herd behavior and underutilization. Across different experiments, we showed up to an 85% latency improvement and a cost reduction of egress traffic by up to 29%.
The following is a relatively complex case that shows our system responsiveness, flexibility, and performance.
Several web applications with microservice interdependence:
We deployed a mix of web applications that share common services, which causes competition between the applications over resources in the system. For example, we can see that both the dashboard service and the user page service are dependent on the main DB service. We show how our solution accounts for the interdependence between different service chains. We deployed the services on five clusters spread across five different geolocations (Brazil, Japan, Germany, US East and West) and over two cloud providers, Amazon Web Services (AWS) and Google Cloud Platform (GCP). Figure 3 is a dependency graph of the different applications.

Figure 3: Multiple applications sharing services dependency graph
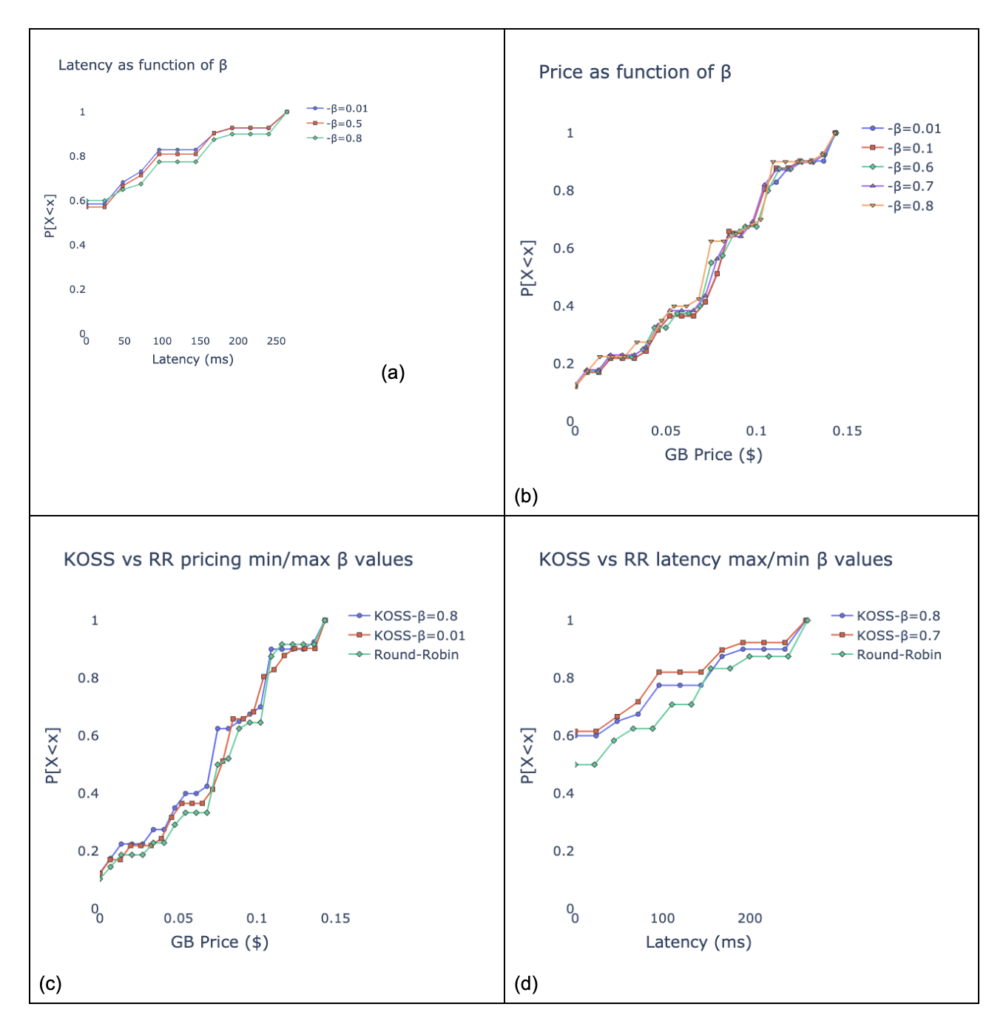
Figure 4 is a series of cumulative distribution function (CDF) graphs: Graphs a and b show the shift in the mean metric (price/latency) according to the change in the β parameter (6). Our technique clearly provides fine-grained control over each parameter we defined for the cost function. Graphs c and d show our superiority over the current round-robin implementation. We show that no matter what the β value we choose, KOSS surpasses the round-robin and improves the mean latency and price per GB. In this layout, we achieved a total cost reduction of up to 7% and a latency improvement of up to 28%.
Conclusion and future work
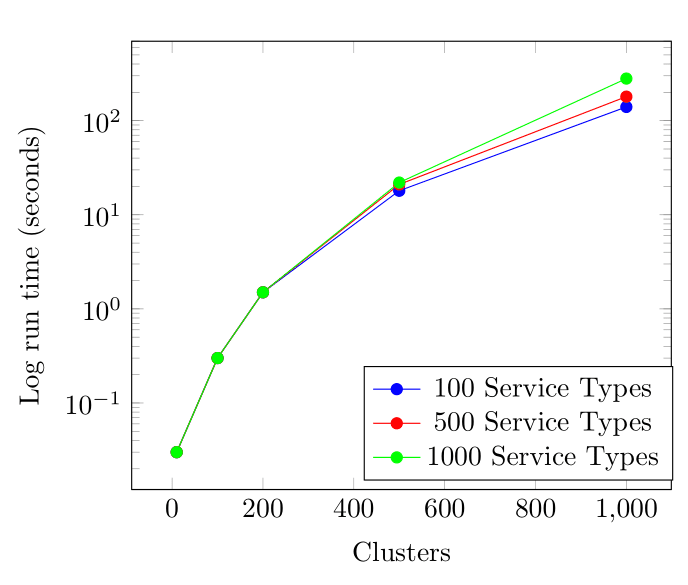
We believe that this research subject has great potential for future work and improvements. As deployments are moving towards thousands of clusters on edge environments, we would like to enable linear degradation in the performance of the algorithm to address the issue of scale. In Figure 5, we show that the performance degradation of the algorithm is not linear. For example, when a deployment has 1,000 clusters or more, it could take minutes for the algorithm to converge.
Another improvement we want to introduce into our system is better utilizing the autoscale mechanism implemented by Kubernetes (Horizontal pod autoscaler) and the different cloud providers (Cluster autoscaler). For instance, we might want to scale a certain service to include more pods behind it in some cases. In this way, the service will increase its capacity and avoid sending requests outside the cluster, which will incur higher latency and traffic penalties. We can also improve the algorithm by allowing access to the full application dependency graph. In that way, we can take into account the whole service chain and make sure to get global optimum, even though this problem was proved to be NP-hard.