




Could a grammarless approach increase its effectiveness?
Low-level systems such as Linux kernels and hypervisors form the foundation of cloud systems today. The virtual machines (VMs) provided by hypervisors are attractive targets for attackers. Bugs in hypervisors create the risk of an attacker in a malicious VM, compromising the isolation guarantees provided by the hypervisor, the underlying system. and the neighboring VMs. Similarly, OS kernels continue to be targets for attackers, as they are often tasked with managing access to hardware and enforcing separation of privileges between processes. A kernel compromised in a VM can place the entire physical system at risk, since an attacker with a VM kernel has complete access to the hypervisor’s virtual-device attack surface.
Fuzz testing has recently become popular as a proactive measure to identify bugs in software before they are exploited. Fuzz testing (or fuzzing) is an automated technique for generating software input and detecting bugs in its execution. Fuzzing has been applied to both hypervisors and kernels; however, the state-of-the-art techniques require extensive manually written grammars to fuzz each individual interface. These grammars create a potential scalability problem, as hypervisors and kernels grow rapidly and outpace manual efforts to create descriptions.
In RHRQ 2:1, we introduced Morphuzz, a technique to fuzz hypervisors (“Fuzzing hypervisor virtual devices”). Since then, our Morphuzz conference paper has been accepted and will appear at Usenix Security ’22. We fully upstreamed Morphuzz into the QEMU (Quick EMUlator) hypervisor and found dozens of bugs. Additionally, we leveraged the lessons learned while developing Morphuzz to create a novel technique for fuzzing OS kernels. This article will describe the improvements we made to Morphuzz that made it successful upstream. We will also briefly delve into how we are applying Morphuzz’ concepts to kernel fuzzing.
Morphuzz upstream
One of Morphuzz’ key benefits is its ability to transparently fuzz complex DMA-based data structures by reshaping the input space.
The Morphuzz fuzzer permits fuzzing virtual devices across all three major input/output (I/O) interfaces—port I/O (PIO), memory-mapped I/O (MMIO), and direct memory access (DMA)—without any specific harnesses or grammars for individual virtual devices. One of Morphuzz’ key benefits is its ability to transparently fuzz complex DMA-based data structures by reshaping the input space. Typically, DMA transfers are performed asynchronously by the device, making DMA fuzzing difficult for a fuzzer operating from the perspective of a CPU. However, Morphuzz applies hooks to the hypervisor to transform DMA into a synchronous operation. This allows the fuzzer to populate data accessed by DMA on demand, just before it is read by the device.
Continuous fuzzing has become an integral part of the software development process for many projects, as it can rapidly catch bugs before they make it into releases. Thus once our original prototype implementation of Morphuzz for QEMU was successful, we were enthusiastic about integrating it into upstream QEMU to enable continuous open source fuzzing.
During the upstreaming process, we developed:
- Documentation for using Morphuzz
- Scripts to fuzz QEMU on the OSS-Fuzz platform, which provides resources to fuzz security-sensitive open source projects continuously
- Tools to unbend and minimize crashes detected by Morphuzz, as well as a script to convert crashes into copy-pasteable reproducers and upstreamable QEMU test cases
The tools, in particular, are important for end users. At its core, Morphuzz uses a simple opcode interpreter to convert inputs received from the fuzzing engine (libFuzzer) into sequences of I/O operations. When Morphuzz finds a crash, it is easily reproduced by simply providing the crashing input to the Morphuzz opcode interpreter. However, QEMU is maintained by close to 200 developers, most of whom may not be familiar with the fuzzing infrastructure. Simply providing binary Morphuzz crashes creates additional work for the developer, who will need to build QEMU with fuzzing support and understand Morphuzz’ essential inner workings. For our upstream integration, it was necessary to provide a mechanism for converting Morphuzz crashes into standard QEMU QTest test cases that developers are familiar with.
QEMU features a simple facility called QTest for creating virtual-device test cases. QTest allows developers to easily create readable unit tests for virtual devices. Morphuzz unbends each crash into a standalone QTest reproducer. It then replays the crashing input through the opcode interpreter and logs the resulting linear sequence of MMIO/PIO and DMA-related device I/O commands in the order they were issued. Since real VMs do not populate DMA buffers on demand, Morphuzz annotates all I/O commands used to fulfill DMA accesses in the log with a prefix. Then, Morphuzz simply rearranges the logged I/O commands so that each command filling a DMA request precedes the direct PIO/MMIO command that triggered it.
The result is a linear QTest API trace, which can be piped into a standard QEMU process to reproduce the crash. We also provide a facility to minimize these QTest traces by removing operations (or parts of operations) unnecessary to reproduce a crash. As a result, we can often reduce several-megabyte-sized QTest traces into several hundred bytes. The QTest trace can be sent to virtual-device developers along with the command line used to specify the connected virtual devices, as a simple, self-contained, straightforward way to reproduce crashes.
We also provide a lightweight tool that can convert Morphuzz’ automatically generated QTest traces into C code that can be committed upstream for regression testing new changes. OSS-Fuzz is continuously running Morphuzz for over 40 virtual device configurations. Due to Morphuzz’ generic design, it usually takes just seconds to add support for fuzzing additional devices. Combining OSS-Fuzz reports with the infrastructure for creating reproducers has led to over 100 bugs reported and 15+ CVEs (common vulnerabilities and exposures) to date.
The kernel’s fundamental role in managing resources and enforcing isolation between applications makes it an attractive target for attackers.
Fuzzing the Linux kernel
The Linux kernel continues to serve as one of the most security-critical building blocks in modern computing. The kernel’s fundamental role in managing resources and enforcing isolation between applications makes it an attractive target for attackers. Recognizing the critical nature of OS security, many fuzzers have targeted OS kernels. Most OS fuzzers focus on the critical system-call interface, which enables user-space applications to request services from the kernel. The state-of-the-art kernel fuzzer, Syzkaller, has reported thousands of Linux kernel bugs. Thanks to its accessibility and automation, Syzkaller has become an integral component of the kernel-development process. However, Syzkaller relies heavily on manually written descriptions for every kernel interface. For example, it features 2,013 lines of hand-written descriptions of the kernel’s KVM interface (used to provide access to hardware-accelerated virtualization). Syzkaller contains tens of thousands of interface descriptions, with many interfaces still missing support.
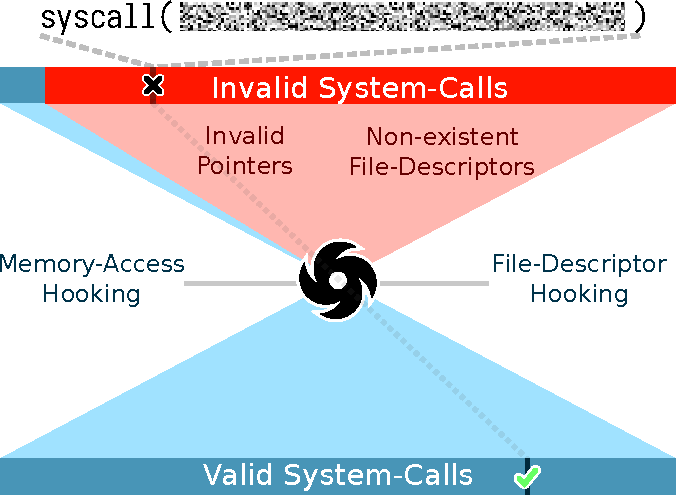
While developing Morphuzz, we noticed key similarities between the virtual-device input space on hypervisors and the system-call input space exposed by kernels. Hypervisors can asynchronously read DMA inputs from any location in guest memory. Likewise, kernels can access data in user-space process memory while handling system calls. Thus, we identified that Morphuzz’ model for fuzzing virtual devices could likely be replicated in the kernel. However, the Linux kernel is a significantly more complex target than most hypervisors. While QEMU has a sizeable 2 million lines of code, Linux has close to 30 million lines. Additionally, unlike hypervisor fuzzing, kernel fuzzing has been an active area of development for decades.
A simple grammarless fuzzer could pass fuzzer-provided integers as arguments to system calls. However, such a fuzzer is quickly rendered useless by the effectively boundless system-call input space induced by pointer and file-descriptor arguments. Fuzzers such as Syzkaller require annotations of struct types, flag fields, enumerations (enums), and constants passed as system-call arguments. Our fuzzer is based on the core insight that instead of relying on extensive system-call descriptions, the system-call input space can be reshaped (much like Morphuzz’ reshaping of the DMA space) to make it conducive to fuzzing. That is, we leverage the APIs used by kernel code to handle system calls to reduce the input spaces associated with memory and files. By reshaping the input space, we can essentially rely on a general-purpose fuzzer (e.g., libFuzzer) to produce complex system-call behaviors. This technique eliminates the need for detailed descriptions and harnesses for individual system calls.
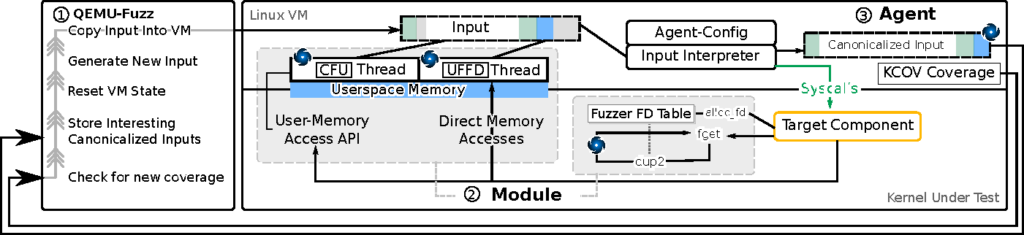
Harnessing the kernel is more difficult than harnessing QEMU (a user-space application). As such, we relied on emerging full VM snapshotting to execute kernel fuzzer test cases in individual VMs, which are rapidly restored from a snapshot after each input. As we mentioned above, file descriptors pose a challenge for kernel fuzzing. File descriptors are passed through system calls as simple integers. A typical process only has a handful of files open. As a result, the semi-random mutations of a fuzzer are highly unlikely to generate an integer system-call argument associated with a valid (i.e., open) file. Even if the fuzzer guesses a valid file-descriptor integer, it would simultaneously need to pick a system call and arguments that are valid for that type of file.
Our fuzzer reshapes the file-descriptor space by hooking the internal APIs used by the Linux kernel to associated file-descriptor numbers with the underlying resources. Then, using the dup2 system call, we associate the fuzzer-provided integers with valid files. This ensures that any fuzzer-provided value interpreted as a file descriptor by the kernel is mapped to a valid open file. Our strategy for user-space memory accesses is similar; we hook the major APIs used by system calls to copy data from user space. However, the kernel provides additional mechanisms to access data in user space, some of which cannot be hooked through a centralized API. To work around this, we applied the Linux kernel’s userfaultfd feature to detect access attempts to user-space memory at the MMU level.
Thus we have two layers of hooks for user-space memory: the centralized API hooks and the userfaultfd hooks. Similar to Morphuzz, at its core, our kernel fuzzer simply interprets binary inputs from a general-purpose fuzzing engine (libFuzzer) into sequences of system calls. Hooks transparently allow the fuzzer to populate file descriptors and complex data structures just in time for the kernel to access them.
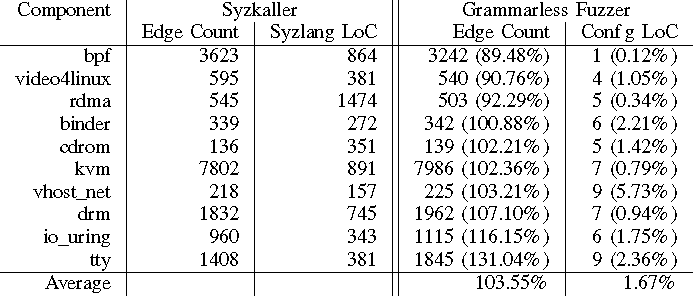
We found that even though our kernel fuzzer does not feature detailed system-call descriptions, it achieves competitive coverage compared to Syzkaller. Furthermore, we found new issues in code already covered by Syzkaller, highlighting that manually written descriptions can often underfit or overfit the interface in question. Our prototype implementation requires only a few lines to add support for fuzzing additional kernel interfaces (1.7% as many lines as Syzkaller’s descriptions) while achieving 103.5% of Syzkaller’s coverage.
Currently, our grammarless solution is completely separate from the kernel’s existing extensive fuzzing infrastructure (based mainly on Syzkaller). Syzkaller benefits from years of contributions by dozens of developers. As such, we hope to integrate our grammarless methods into existing kernel fuzzing code, which provides extensive facilities for creating reproducers, identifying commits that introduced bugs, and detecting regressions. Furthermore, Syzkaller can simultaneously fuzz an entire kernel, while each instance of our grammarless fuzzer focuses on an individual kernel component. Since bugs often lie at the intersection of a complex combination of kernel features, we are actively investigating ways our grammarless approach can be improved to fuzz all system calls without negatively impacting fuzzing performance. We are also working towards integrating a VM-snapshot-based fuzzer into upstream QEMU (this is the subject of a Google Summer of Code 2022 Project).
The Linux kernel is growing rapidly, and security efforts need to advance just as quickly. We found that it is possible to decrease the reliance of kernel fuzzers on manually written descriptions while maintaining competitive coverage and bug-finding performance. We are excited to see the potential of grammarless approaches when combined with modern fuzzing techniques, and we are actively investigating ways to upstream parts of our kernel fuzzer so that it may serve the Linux community for years to come.