

Data silos, regulatory compliance, and resource consumption limit the collaboration needed to address real-world challenges. A global consortium is working to change that.
Significant challenges have hindered the rapid integration of artificial intelligence (AI) in key industries that drive economic and social development such as agriculture, finance, and energy. Shared data can provide substantial efficiency benefits, enabling more effective and sustainable processes. However, datasets isolated due to privacy considerations, data interoperability challenges from incompatible frameworks, and data sovereignty principles under regulations like GDPR create substantial barriers to collaboration.
AI also creates energy consumption challenges. Large-scale model training is hampering efforts to reduce emissions, in turn causing delays in transitioning to green sources of energy, in direct conflict with sustainability initiatives. Compounding these issues is the absence of consistent methods for measuring, let alone reducing, the energy consumption of AI workloads.
The GREEN.DAT.AI project addresses these challenges by applying its solutions to real-world problems in four major industries, across six distinct use cases (UC):
In the energy sector, UC1 and UC2 provide solutions to enhance efficiency and security in the renewable energy market and in EV charging.
- In agriculture, UC3 and UC4 improve resource management for farming and water management.
- In the mobility sector, UC5 demonstrates enhanced energy demand optimization and refined data analytics for an e-bike network.
- In finance, UC6 provides robust fraud detection solutions that ensure compliance.
A framework for sustainable AI
As a solution to these challenges, the GREEN.DAT.AI project, funded by the Horizon Europe research grant program*, launched in January 2023. The project unites a consortium of 18 partner organizations from 10 EMEA countries to design and develop an energy-efficient AI-ready data space supported by a toolbox of AI services. These services are leveraged across various industry UCs to showcase the project’s substantial benefits. By drawing on the International Data Space (IDS) framework, ecosystems such as the GREEN.DAT.AI data space ensure interoperable, GDPR-compliant data sharing that adheres to standardized exchange protocols. This reinforces data sovereignty by empowering organizations to retain control over their data within a trusted network.
The following section details the project’s reference architecture, a key output of which illustrates the core components and services that bring this vision to life. We will explore how common services, the AI toolbox, and other key elements are integrated to enable efficient and secure data sharing.
Reference architecture
A data space (DS) is a decentralized and secure data-sharing ecosystem where multiple organizations can share and access data while maintaining control and sovereignty over their own. The GREEN.DAT.AI Reference Architecture, shown in Figure 1, details an implementation of this project’s AI-ready data space that delineates roles: Data Providers manage data ingestion; Service Producers develop and deploy optimized and energy-efficient AI tools and services; and DS Common Services facilitate data discovery, access, and interoperability through defined standards like DCAT-AP and RDF.

DS Common Services ensure adherence to the FAIR principles of data management (Findable, Accessible, Interoperable, Reusable) through a data catalog, a component that makes datasets discoverable and understandable. The catalog, implemented by Red Hat engineers, is Piveau. It provides all three required components: a data catalog with a user-friendly interface for dataset discoverability and understandability; a vocabulary hub, which provides standardized terminology for interoperability; and a metadata broker, facilitating the discovery and exchange of metadata between different data sources. The architecture also integrates secure data transfer components, including Eclipse Data Connectors (EDC) and Apache Kafka, enabling privacy-preserving exchanges and ensuring GDPR compliance within a secure, sovereign data-sharing environment.
This architecture is the foundation for the project’s core innovations, which include a dedicated Energy-Efficiency Testing Tool and a comprehensive AI services toolbox. The toolbox includes advanced capabilities such as Federated Learning, Explainable AI, and AutoML, all designed to support the development of sustainable and transparent AI solutions. The testing tool is incorporated to validate the energy efficiency of these services, ensuring they meet the project’s sustainability goals.
Energy-Efficiency Testing Tool
The Energy-Efficiency Testing Tool is a key part of the project’s strategy to address the energy consumption challenges of AI. It provides a standardized way to measure the performance of AI algorithms from several perspectives: energy consumption, model precision, data volume, and time. By capturing these metrics, the tool can establish a baseline for an algorithm’s initial performance. Subsequent iterations of the algorithm are then tested against this baseline to measure the impact of changes and validate improvements in energy efficiency.
The testing tool also includes an intelligent Co-pilot agent that uses reinforcement learning to propose new, optimized configurations to users. This agent learns from the outcomes of past tests and suggests configurations that balance high performance with low energy consumption. This automated approach helps ensure that the project’s services consistently meet or exceed the goal of reducing energy consumption by 10+%.
Energy-efficient AI services toolbox
At the core of the project is a toolbox of 21 AI services. This includes generalized services that support foundational processes, such as data-enrichment tools to improve data quality. The toolbox also provides more advanced services, such as Federated Learning frameworks that enable collaborative training on private data, Explainable AI tools that bring transparency to complex models, and AutoML services that intelligently optimize the development of new models. Collectively, these services prioritize environmental sustainability and regulatory adherence while supporting a range of industry requirements across the UCs.
Federated Learning
Federated Learning (FL) is an innovative approach to AI that allows multiple organizations or devices to collaborate on building a powerful AI model without ever sharing their raw, private data. This approach breaks down data silos and makes models more accurate for a common objective. It’s particularly useful for industries with strict privacy regulations, such as banking or healthcare, but applicable for other industries as well.
For example, in Use Case 3 (UC3), farms want to train a model to optimize fertilization. Instead of sending sensitive farm data, such as soil-health tensors or nutrient sensor readings, to a central server, each farm keeps its data local. They train a version of the model on their own data and then send only their updated model, rather than the data itself, to a central coordinator. This coordinator aggregates the model updates from various farms and sends an improved global model back to each. This enables the model to learn from a massive, collective dataset while preserving the privacy of each farm’s information. The project also applied FL to wind energy in UC1, where different power plants improved their energy production forecasts by collaborating without revealing their proprietary operational data. This approach directly addresses regulatory compliance rules like GDPR by keeping sensitive data on-site.
The service also has significant environmental and performance advantages. Compared to centralized model training, local model training drastically reduces the need for large-scale data transfers and energy consumption by only sharing small model updates. Results showed an optimized federated approach could consume 52% less energy than a centralized one, as seen in Figure 2, demonstrating that FL is not only a privacy-friendly solution but also a key strategy for making AI more sustainable.

Figure 2. Total energy consumption of centralized model (blue) vs. optimized federated model (yellow)
Explainable AI
A major barrier to the adoption of sophisticated AI models is their black-box nature. As models become more complex, it becomes nearly impossible for humans to understand how they arrive at a specific decision, which erodes trust and makes it difficult to comply with regulatory requirements. The need for transparency is especially critical in sectors like finance, where AI decisions about fraud can have serious consequences. This is the problem that Explainable AI (XAI) is designed to solve.
XAI services are designed to make complex AI models transparent and understandable. For example, in fraud detection for banking UC6, a bank needs to know not just that a transaction is fraudulent, but why the AI flagged it. This service provides tools like SHAP and LIME, which can explain an AI’s decision by showing which data features had the biggest impact on the outcome. These tools build a simple, easy-to-understand model around a specific prediction to explain it, allowing users to trust the AI’s judgment and understand its reasoning.
The project’s toolbox includes a related service called Explainable Feature Learning, which automatically creates new, powerful features from raw data to improve an AI model’s performance. Most importantly, it does so while ensuring the features are still interpretable, so experts can understand how the new features relate to the original data. This service is particularly valuable for tackling data complexity without sacrificing transparency.
The project demonstrated that these tools are not just for explanation; they can also be optimized for efficiency. An experiment with the Explainable Feature Learning service showed that by adjusting the settings to limit the number of features created, the model could achieve the same level of accuracy while consuming over 94% less energy (Figure 3). This shows that the process of making AI more transparent can be done in a highly energy-efficient manner.
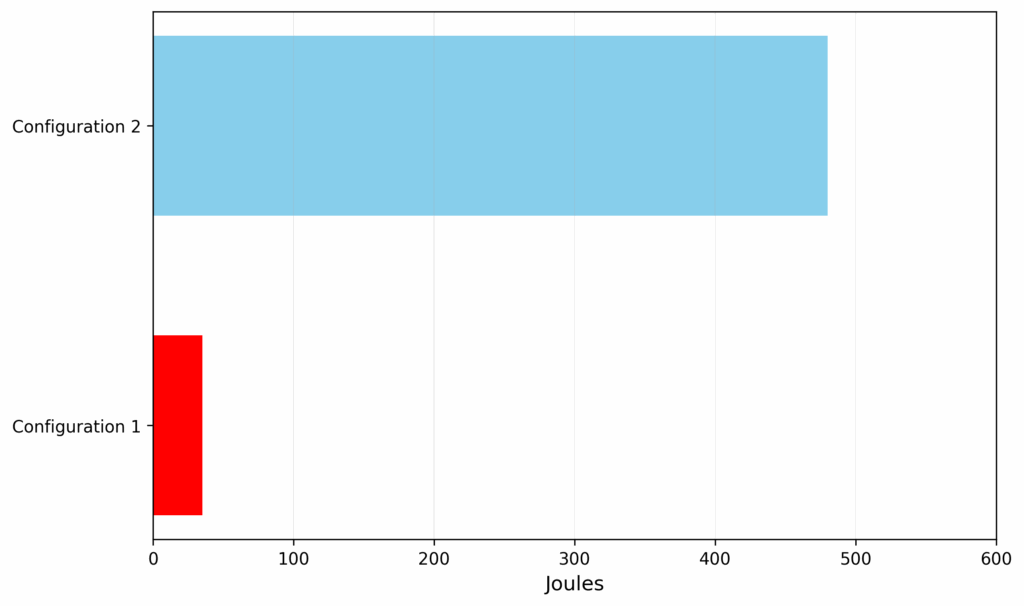
created features using feature learning (measured in Joules)
AutoML: algorithm selection and hyperparameter tuning
Another obstacle to efficient deployment of AI is the labor-intensive, computationally expensive process of algorithm selection and hyperparameter tuning, or AutoML. This task requires trying out many different models and configurations to find the one that performs best for a specific dataset. This trial-and-error method is time-consuming for developers, and it consumes a vast amount of energy, directly conflicting with the sustainability goals. To automate and accelerate the process, the project developed an AutoML service that uses optimization and meta-learning techniques. Instead of searching every possible combination of configurations, the service intelligently narrows options and learns from each trial to select the next most promising configuration. This drastically reduces the number of trials needed to find a high-performing model, which, in turn, saves considerable amounts of energy and time.
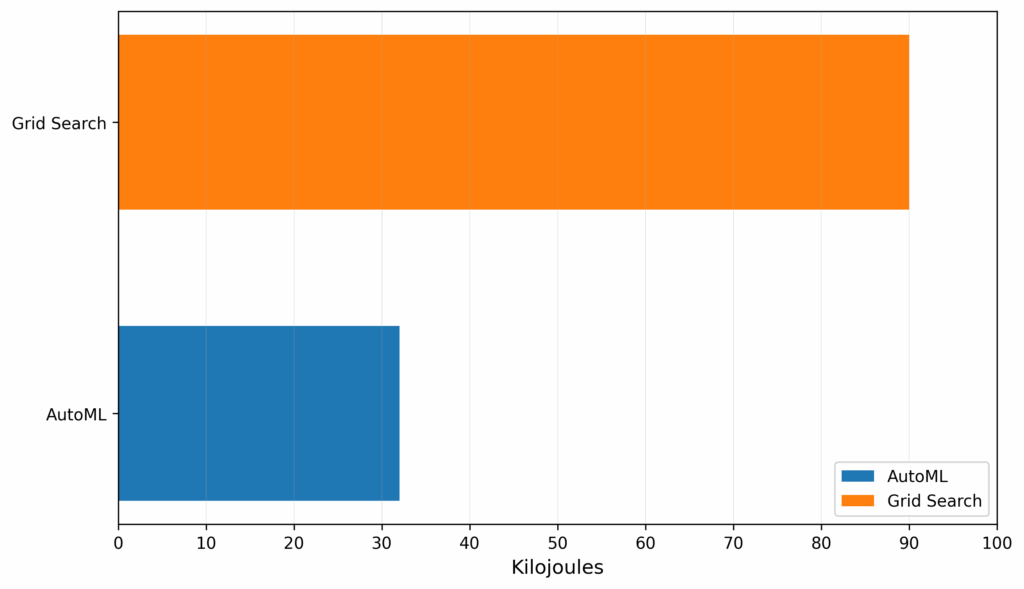
The service is applied to the smart mobility UC5 to address the challenge of e-bike redistribution. The goal is to predict bike demand at various stations to prevent shortages or surpluses. Using the AutoML service to quickly and efficiently find the best forecasting model for each station, the system can provide an optimal plan for moving bikes where they are needed. In a head-to-head comparison with a traditional exhaustive search (Grid Search), the AutoML service achieved a 64% decrease in energy consumption (Figure 4), making it fundamentally more energy-efficient and sustainable.
Key takeaways
Ultimately, the GREEN.DAT.AI project is a holistic, open-source-driven vision where AI is not only accurate but also sustainable, transparent, and respectful of data sovereignty. The project successfully addresses the intertwined challenges of data silos, regulatory compliance, and energy consumption in the AI era. Its holistic vision is realized through an innovative toolbox that enables sustainable and responsible AI deployment. The project’s architecture, built on principles of data sovereignty, ensures interoperability and GDPR compliance through services like the EDC Connector and Data Catalog.
The Federated Learning framework breaks down data silos and allows organizations to train powerful models collaboratively without ever sharing sensitive data, an approach that supports regulatory compliance while achieving significant energy reductions. The Explainable AI and AutoML services further drive efficiency by making complex models transparent, while automating the optimization of development processes, which reduces computational waste. These services are all validated by the project’s Energy-Efficiency Testing Framework, ensuring that every advancement aligns with the core objective of reducing AI’s environmental footprint by at least 10%.
Concluding in December 2025, GREEN.DAT.AI project’s final steps are focused on validating the results of the UCs and ensuring the technology is fully interoperable. By exchanging data with external systems and data spaces through data connectors, the project demonstrates that this solution can scale and function within a broad, interoperable ecosystem.
Red Hat engineers on the project team are Ben Capper, Leigh Griffin, Clodagh Walsh, Ant Carroll, and Ray Carroll. For more information, including documentation of all use cases, visit the project homepage (greendatai.eu), and find GREEN.DAT.AI on LinkedIn or X.

*GREEN.DAT.AI is funded by the European Union under Grant Agreement No. 101070416.