
By José Bolina
Building distributed systems is complex work, but strong primitives with well-defined guarantees and an expected behavior can make it easier. With stronger guarantees in primitives come strong safety and correctness verification requirements. In some cases, applications are dependent on these guarantees to work, for instance, a strongly consistent distributed database deployed across regions or a key-value store for cluster metadata. In such scenarios, the system provides clients with the most recent written value regardless of which client is requesting. Testing and verification lie on the developers’ shoulders to provide a correct implementation of this intricate system.
This article will discuss the Raft algorithm and how we verified the correctness of the implementation in jgroups-raft, a project within Red Hat that implements the Raft algorithm. The reader will learn about the correctness of distributed systems that offer strong guarantees and how violations might happen. The code utilized for the results shown here is available on GitHub.
Raft, in a nutshell
Raft is an algorithm for solving distributed consensus, providing users with a primitive for building a strongly consistent system. Such a system tolerates failures, nodes crashing, and network partitions while continuing to guarantee strong consistency. On the other hand, the whole system becomes unavailable when most nodes somehow become unavailable, as it can not safely proceed and hold its guarantees.
Oversimplifying how Raft works, an election happens, and one node in the cluster is elected the leader. Every request goes through the leader, which asynchronously replicates the data to the other nodes. Once the leader successfully replicates the data to the majority, it persists the data in a log for recovery and replies to the user’s request. All nodes receive the operations in the same order. The algorithm tolerates different failures, for example, network partitions, crashes, and restarts. And by making all these strong arguments, the algorithm is formally verified.
Getting to know jgroups-raft
The project we verified, jgroups-raft, is a feature-complete implementation of the Raft algorithm. Since it builds on top of JGroups, we can take advantage of the mature and battle-tested features, including the flexible protocol stack, which includes encryption, compression, and reliable transport. Most notably, JGroups also include group membership events advertised to all nodes in the cluster in the same order containing the current view of members. jgroups-raft uses the group membership from JGroups to build a stable election algorithm. Leaders can step down when a majority is lost, and the membership events from JGroups help to avoid nodes disrupting the cluster by starting unnecessary election rounds. Other useful functionalities include cluster membership reconfiguration, as in the Raft paper, with one change applied per operation and snapshots of the state machine and log compaction.
The project already includes the usual development format with unit tests. But as we introduced features in Infinispan relying on jgroups-raft, we decided it was time to add a more robust verification. In our search for a tool to verify implementations, we came across Jepsen.
Jepsen tests
Jepsen is a framework for verifying distributed systems. Jepsen has available analyses of multiple systems tested throughout the years, including etcd, PostgreSQL, and others. The code for the verifications is also available, with guides and tutorials teaching how to create a test. We decided to use Jepsen because it is a well-known tool in the community for this kind of verification, with a record of identifying problems in real-world systems.
Jepsen deploys a system in multiple (previously) configured nodes and utilizes clients on a host to issue operations. Since it controls the whole environment, it keeps track of requests and responses on the client side and injects different types of failures on the system side. After the test finishes, a checker runs to verify for violations. All aspects of verification—such as operations, the checker, faults, and violations—are configurable to fit the systems’ requirements.
Test structure and findings
We verified jgroups-raft for different aspects: verifying the building blocks for linearizability violations, membership operations, and invariants from the algorithm definition.
What is linearizability? More informally, linearizability is a property noticeable from the client’s perspective, where every operation seems to take effect atomically as if applied to a local copy, even if, in reality, multiple servers hold the data. This property applies to a single object, although the granularity might vary. For example, a key-value store is linearizable for operations in a single key-value pair but not with multiple pairs at once. Linearizability is easily confused with serializability from transactions.
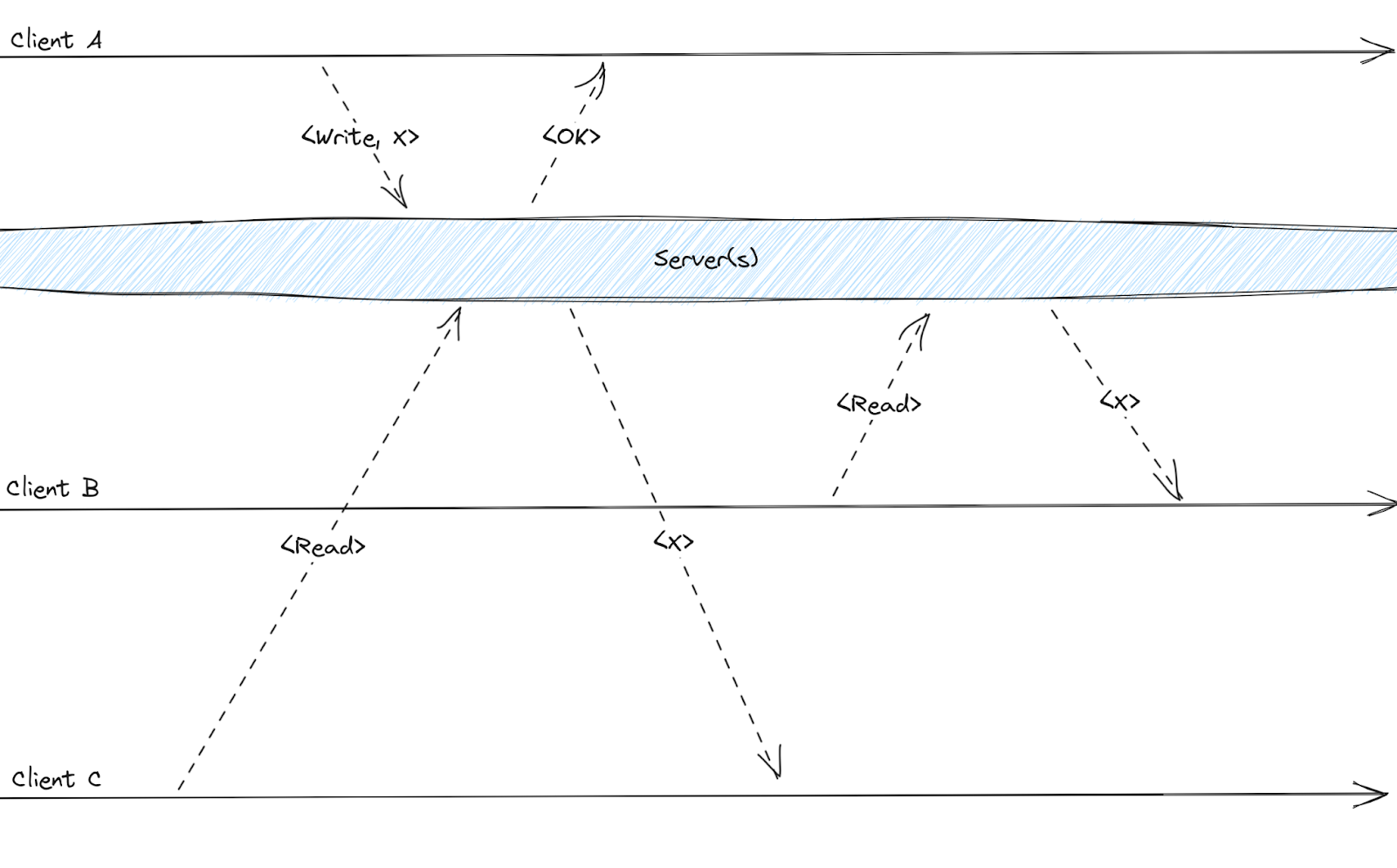
The figure above shows a linearizable system. Client C’s read operation is concurrent with client A’s write, meaning C could receive either the new or old value as a response since either can finish first. Because C saw the effect of A’s write, all subsequent read requests will, too.
Linearizable primitives facilitate the reasoning of the interactions in the system because data behaves as a single copy. jgroups-raft provides a replicated map and a replicated counter as a building block. These blocks work as a replicated state machine, applying operations deterministically. Both the blocks are linearizable.
Building blocks
During our tests, we identified a problem with the read operations for the replicated map. The read operation did not go through the Raft algorithm and instead executed a local read. As writes replicate asynchronously, reads returned locally contain possible stale data.
The figure below illustrates this violation, where the red server is the leader, and CAS means a compare-and-swap operation. Our solution to this problem was to provide a runtime configuration to execute a local or consensus read, as seen in this pull request. The counter block already had this option for reads.
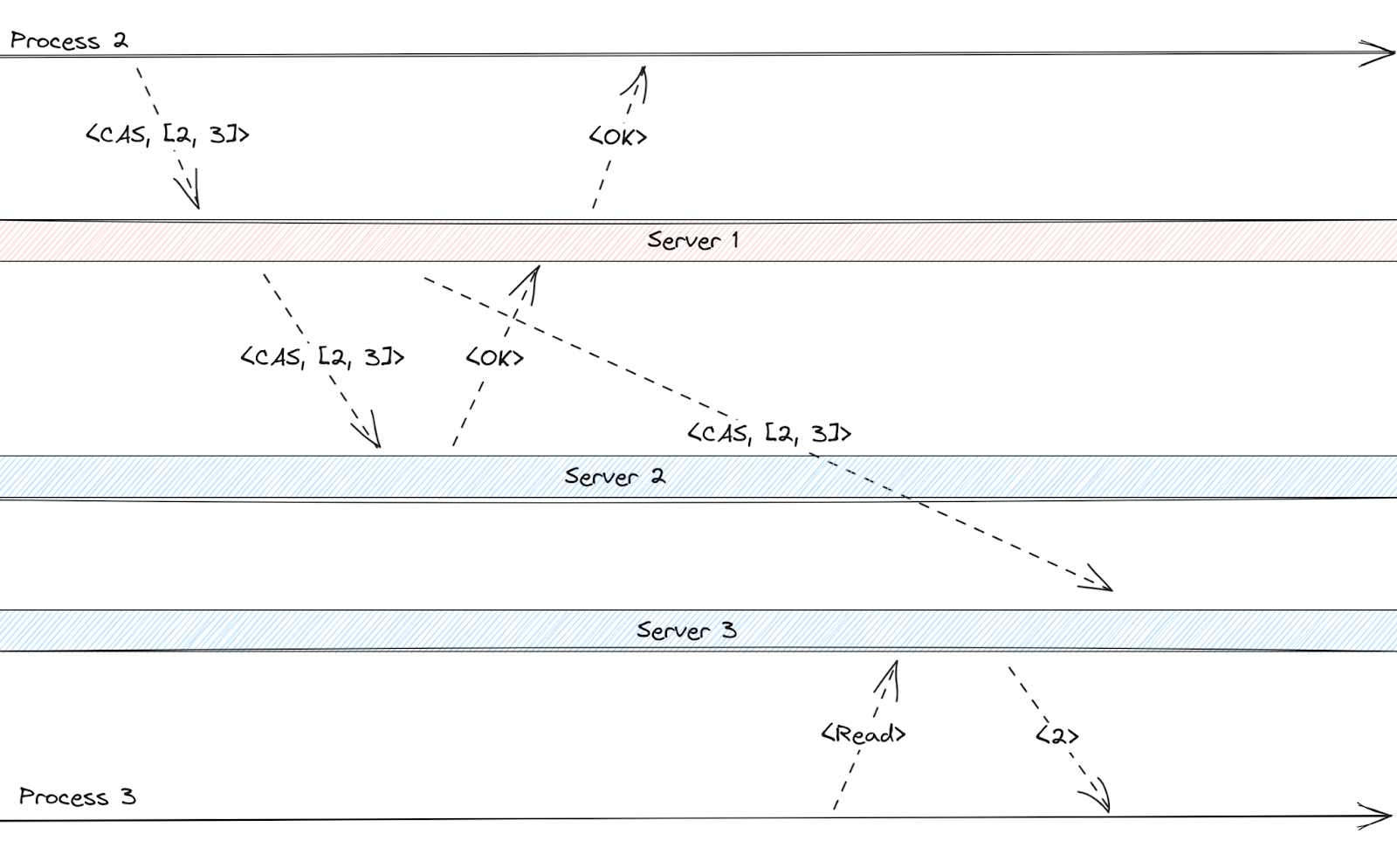
To verify this execution yourself, pass option `–stale-reads` when running the tests. This option enables the local reads for nodes, leading to the linearizability violation.
Membership changes
In addition to checking the building blocks, we also verify membership changes and invariants from the algorithm. jgroups-raft has a CLI utility to apply changes to the cluster topology, adding or removing servers one at a time. The script executes a helper client available shipped with jgroups-raft. The client connects to a running server and issues the membership operation that must go through the algorithm and replicate the change.
We identified a couple of bugs in the CLI command when applied to a cluster with nodes failing. For example, issuing the membership operation through a node that crashes would hang on the client side, waiting for a response. More details about the problem are available on this issue in GitHub.
Raft invariants
The Raft algorithm has some invariants that must hold for safety and correctness. The election safety invariant states that any given term has at most one leader elected. If we retrieve the leader of all nodes in the system at the same instant, nodes can have different results, but never for the same term. Such a mechanism is convenient when redirecting requests from a client to the current cluster leader.
Since Jepsen has a deus-ex-machina view of the system, we implemented an invariant check for election safety. We identified violations in jgroups-raft. We solved this issue by isolating the algorithm state and making any update atomic, generating a simplified state machine. The figure below shows the tight relation between the state variables.
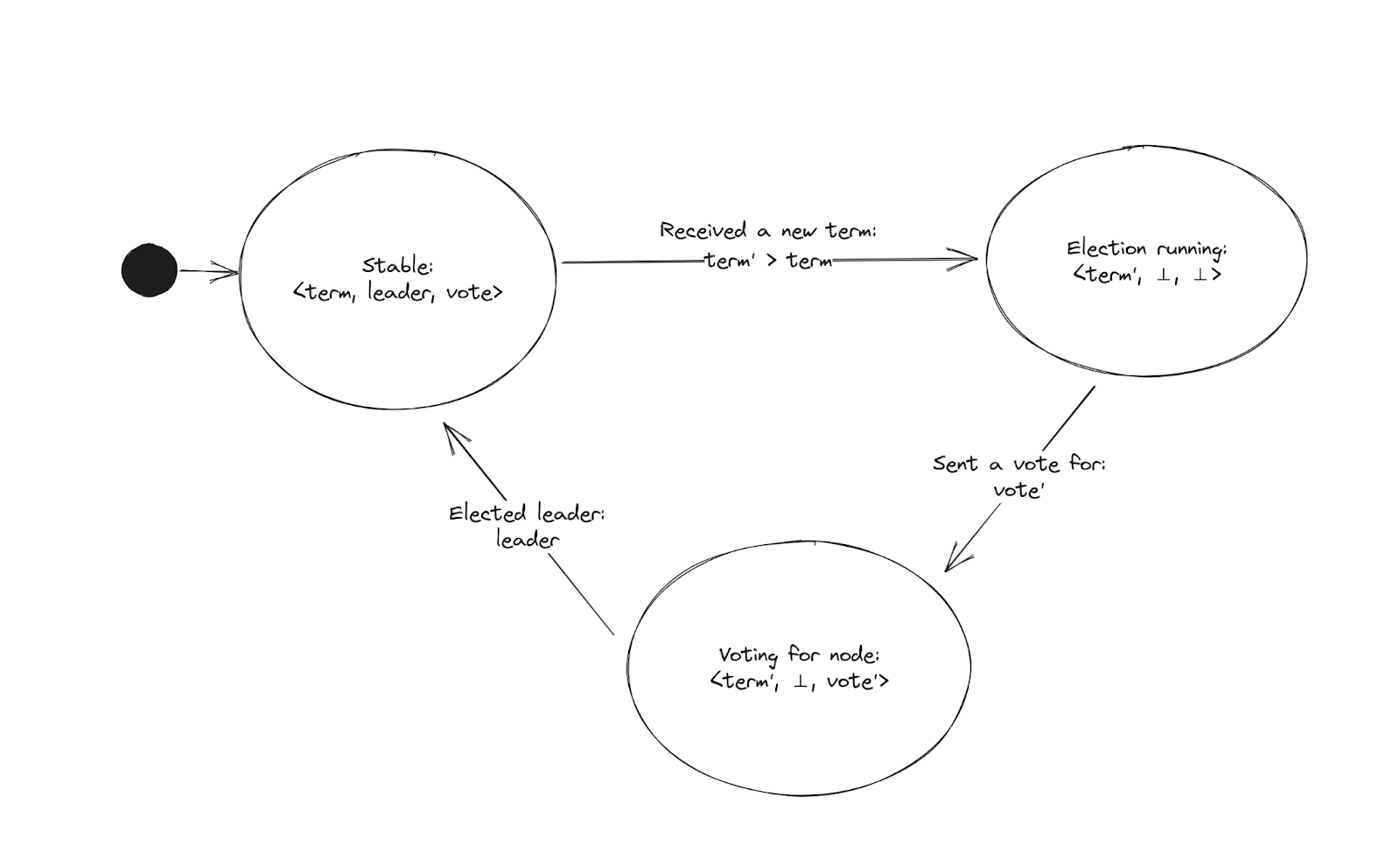
Without an atomic update, a client could see a new leader associated with an older term. This close relationship between the values might not be straightforward at first. Resources like the TLA+ specification make this relation more explicit, where it is crucial for the invariant. Our solution is available in this pull request.
Conclusions
Just with some tests, Jepsen identified issues our test suite did not. In addition, Jepsen collects all the necessary information to make the investigation process easier. Jepsen was flexible enough to verify varying cases, ranging from client-server interactions to CLI scripts and invariants.
The tests we developed for Jepsen are a milestone in our development process. We have the tool to identify if we break anything, and we can introduce new features and fix bugs with greater confidence. Although such a tool is not infallible, it only finds bugs through execution, meaning that Jepsen might not find unlikely scenarios that lead to violations. For example, this GitHub issue describes a concurrency problem that our test suite found with a specific scenario that would lead to a liveness problem, where a node doesn’t receive a message from the leader. The combined forces of all the test suites make the system more reliable.
This research evaluating jgroups-raft raises the question of the quality and assurances of data-intensive libraries and systems. Just because an algorithm is correct in theory does not mean the implementation is. In the theoretical field, proposing a new algorithm involves providing lots of proof of correctness. We believe implementation for critical components should also include more rigorous correctness verification. Although not a silver bullet to all issues, such an approach could improve the safety and correctness of services in the industry.
In the RHRQ article “Anchored keys: scaling of in-memory storage for serverless data analytics,” you can learn more about Infinispan and the development of new structures to meet the CloudButton project requirements for in-memory storage.
About the author

José Bolina is a Software Red Hat Software Engineer based in Brazil.







