Test Case Prioritization: Towards Efficient and Reliable Continuous Integration
Automatic regression testing is a crucial step of any CI/CD pipeline. Its primary goal is to detect bugs and defects introduced by recent changes as early as possible while keeping verification costs at a very low level. An ability to perform regression testing efficiently and effectively (i.e., within a small timeframe yet catching the majority of the bugs) would allow developers to rapidly deliver reliable software updates to the users.
Unfortunately, the regression testing process in modern large-scale software products tends to be much more complex and cumbersome than desired. As the size of the software increases, the test suite also grows bigger and requires more time and resources to be fully executed. In many cases, the time to run the entire test suite can reach 3-4 days or even a week. Consequently, executing all available tests during the CI/CD regression testing procedure is highly impractical and, in many cases, completely infeasible.
To address this issue, test case prioritization (TCP) methods have emerged. Test case prioritization aims to order a given set of test cases such that, the earlier a test appears in the resulting order, the higher is the probability for this test to detect a bug or a fault introduced by the given code change. Provided such an ordering on the entire test suite, the regression testing procedure can iterate over it starting from the beginning and advancing until a predefined limit on the maximal testing time (say, 1 minute) is reached. As the most significant test cases are executed first, the chances of early fault detection rise while still only executing a negligible part (say, 1%) of the entire test suite.
In recent years, TCP solutions have been adopted by major industry players and have spawned a wave of academic research projects. However, the full potential of TCP in regression testing is yet to be explored. As of now, the most widely used approaches are mainly based on heuristic search strategies and/or code coverage methods. In contrast, methods based on machine learning in general and deep learning in particular are barely explored. Closing this gap and devising a ML-based TCP tool is the primary goal of this project.
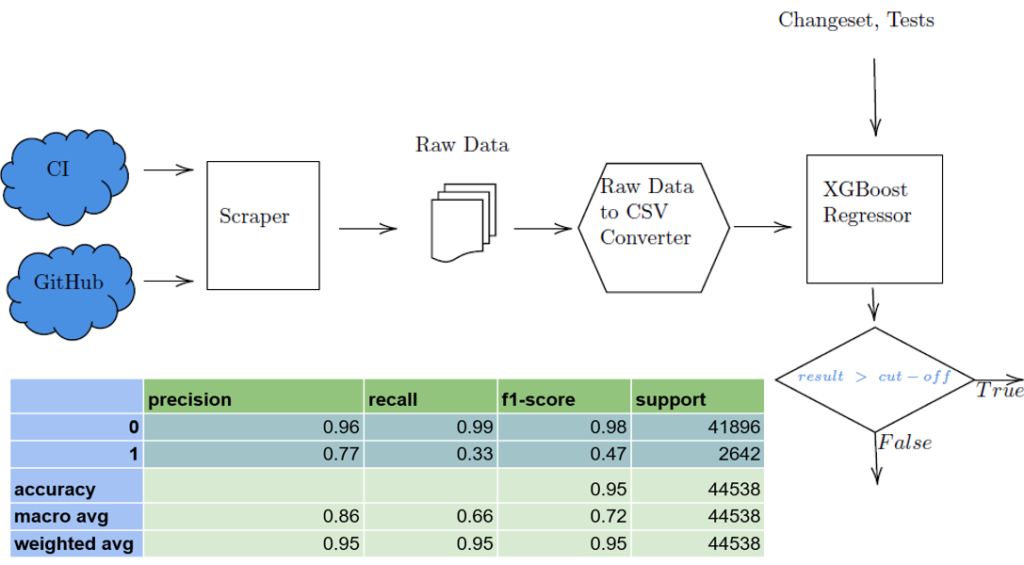
The figure at the top of the page illustrates the proposed structure of our TCP solution as well as the preliminary results obtained by training a simple regression model based on XGBoost. As an immediate next step, we will be looking to improve the quality of results by considering a variety of advanced deep learning methods.
Those interested in finding out more about the TCP project and/or looking for collaboration opportunities are kindly invited to contact Dr. Ilya Kolchinsky (ikolchin@redhat.com) or Gil Klein (gklein@redhat.com).