











The strategy for scaling data capacity varies according to volume, access patterns, and cost-effectiveness. We look at an approach that achieves optimal results in the context of serverless data analytics.
Big data holds great promise for solving complex problems, but data-intensive applications are necessarily limited by the difficulty of supporting and maintaining them. The CloudButton project has created a serverless data analytics platform to democratize big data by simplifying the overall lifecycle and programming model using serverless technologies. Working together, the CloudButton project partners have created a FaaS (Function-as-a-Service) compute run-time for analytics that overcomes the current limitations of existing serverless platforms.
A key component of the CloudButton architecture is Infinispan, an open source in-memory data grid providing a key-value data store that distributes data across elastically scalable clusters to guarantee high performance, high availability, and fault tolerance. Infinispan can serve as both a volatile cache and a persistent data store.
The CloudButton runtime leverages Infinispan as a mutable shared-memory store for input and output data and intermediate results used and produced by serverless functions. While Infinispan addressed CloudButton’s functional and performance requirements, we determined that its scalability model was not a good fit for the lifecycle of serverless workloads in a cloud environment. This article illustrates how we enhanced Infinispan to suit our needs.
Infinispan’s distributed storage
Infinispan stores data in memory using the following scheme. Key-value entries are stored in data structures called caches, which can be replicated or distributed. In replicated caches, all nodes have a copy of all the entries. In distributed caches, a fixed number of copies of any entry is stored across nodes. This allows distributed caches to scale linearly, storing more data as nodes are added to the cluster. Keys are mapped to nodes using a consistent-hashing1 algorithm (currently MurmurHash3). These nodes are known as the primary owners.
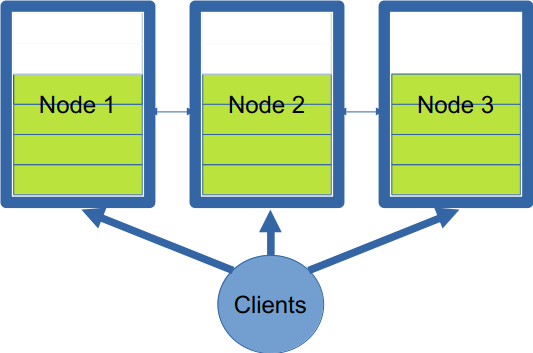
Copies are replicated to other nodes, known as backup owners. These are chosen using anti-affinity rules to avoid colocation on the same server, rack, or site. For convenience, the consistent-hash space is divided into equal-sized segments. Remote clients are aware of the consistent-hash and segment allocation, allowing low read/write latency by performing operations directly with the primary owners in a single network hop. When nodes are added or removed, a rebalancing algorithm redistributes segments to nodes. The strategy attempts to minimize the number of ownership changes and, therefore, the amount of data to transfer. The state transfer algorithm is non-blocking: clients continue to read/write entries, which are transparently redirected to the appropriate owner (see Figure 1).
This approach works well when the operational capacity is known upfront or changes infrequently. In these scenarios, priority is given to data integrity during node failure and the performance of a stable cluster. The rebalancing that occurs after adding or removing nodes has a noticeable impact on the network and the CPU, potentially introducing unwanted latency. In a cloud environment, however, consuming resources for capacity that may not always be needed is not economical. Instead, the cluster should be just big enough for the data it contains. This also means that, if possible, it should scale to zero nodes if there is no data.
Anchored keys
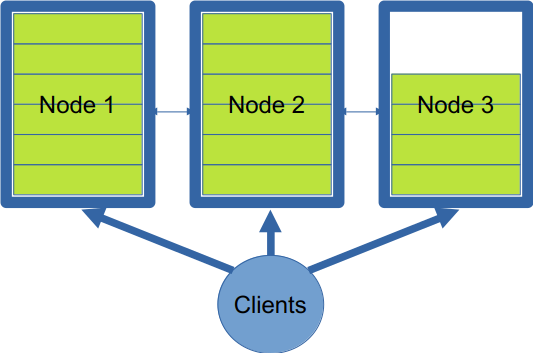
To address the above scale-to-fit scenario, we implemented a scaling strategy called anchored keys. Anchored keys relax some of Infinispan’s distribution rules to remove the impact of state transfer by not rebalancing data when nodes are added.
In this implementation, the primary owner of new keys is the last node in the cluster. Writes can be issued against any node, but they will be applied only by the primary owner. The key-to-node mapping is stored in a secondary, replicated cache, which is accessible by all nodes in the cluster. A node is filled with data until it reaches its capacity. When a new node is added, only the key-to-node mapping cache is replicated to the new node. This is much cheaper than rebalancing the full entries with the values.
Without a predictable hashing strategy, clients can no longer determine the owner of a particular entry and must operate in a round-robin balancing mode. As the size of the cluster increases, the likelihood of a request hitting the primary owner of an entry decreases, significantly impacting latency. This only affects reads, since writes will always go to the node added last to the cluster (see Figure 2).
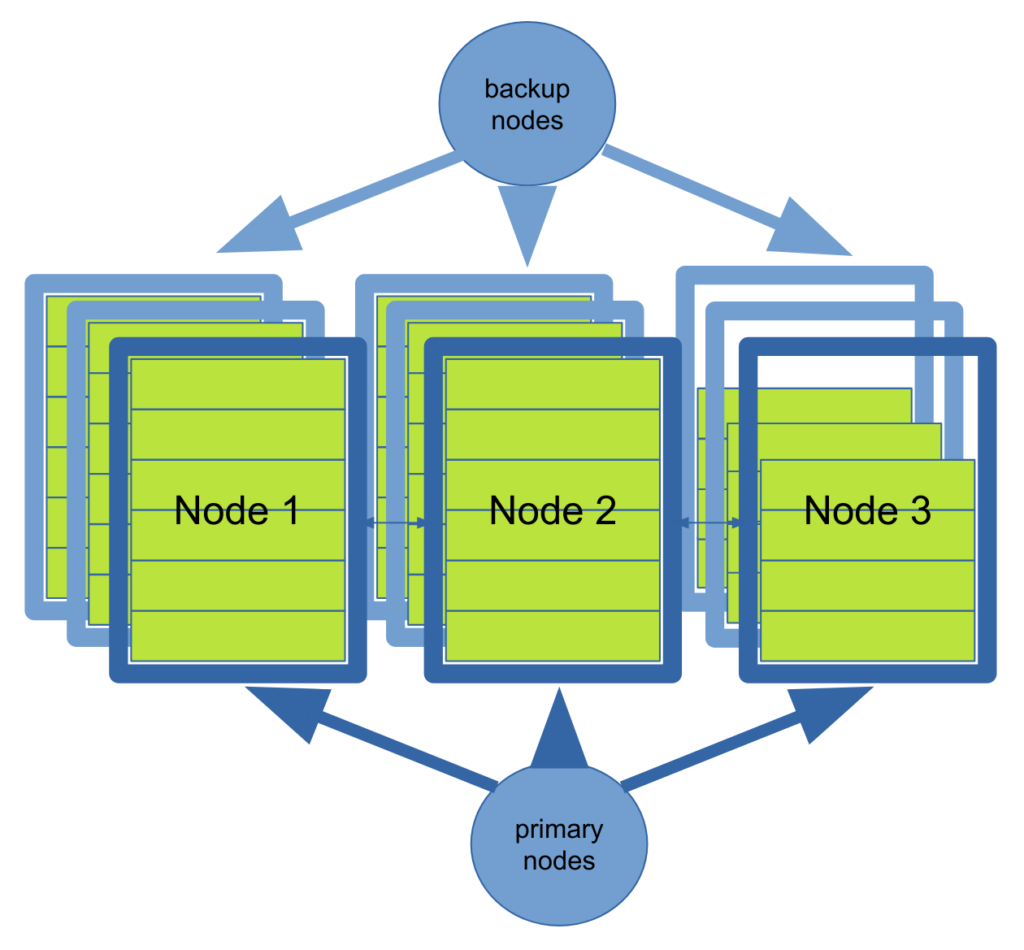
Anchored keys and fault tolerance
To address the need for fault tolerance when using anchored keys, we need to bring back the concept of primary and backup nodes. Each node will, therefore, be associated with one or more backup nodes: writes destined for a node will be replicated to all of its backups. The primary and its backups form a replica group. If one of the nodes fails, it is replaced by one of its backups, a new backup node is started, and data is replicated to it from the survivors in its group. Figure 3 illustrates the architecture of this approach.
A drawback of introducing fault-tolerance to anchored keys is that nodes are assigned a role, either as primary or backup. This asymmetric nature makes managing their lifecycle significantly more complex: in the rebalancing architecture, all nodes are symmetrical and interchangeable.
Performance comparison
State transfer
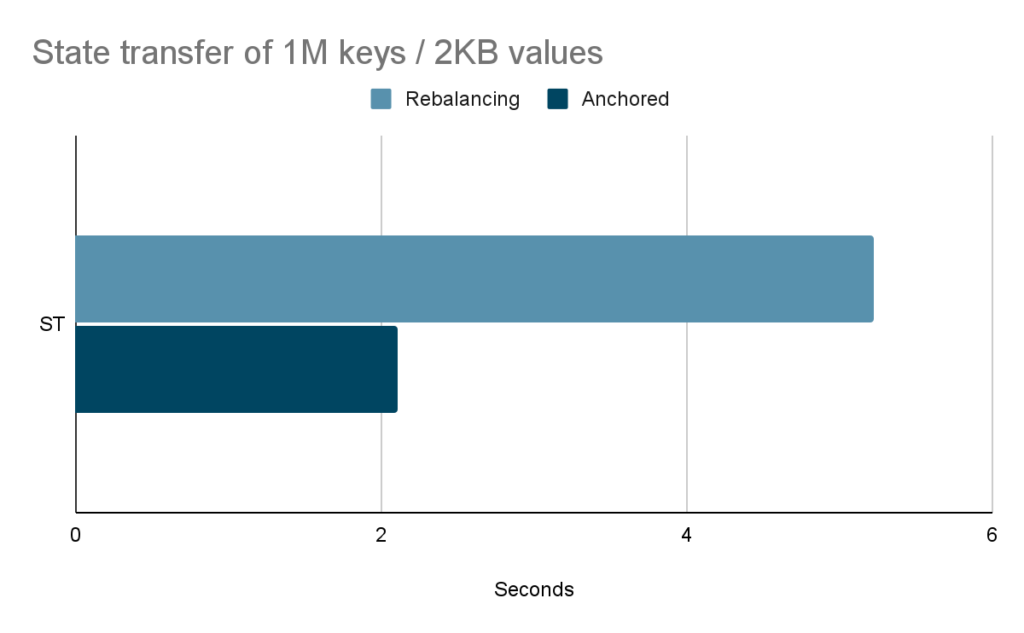
The advantage of using anchored keys over rebalancing becomes significant in the context of rapid scaling as desired in a serverless environment. Figure 4 shows that state transfer in the anchored keys mode is nearly 2.5 times faster than in rebalancing mode when dealing with 1 million entries, each storing a 2KB value. As the size of the values increases, the savings become even more significant since anchored keys do not need to transfer them.
Reads
Because anchored keys trade scalability performance for data-access performance, it’s important to show the impact of its storage strategy on regular reads and writes. Infinispan’s default consistent-hashing client intelligence ensures that reads and writes maintain near-constant performance, no matter how large the cluster.
Because anchored keys forego the benefits of consistent hashing, we have to resort to Infinispan’s basic intelligence, which is applying a round-robin algorithm on the nodes in the cluster. This means that, as the cluster size increases, the probability of a client interacting directly with the primary node decreases, thus causing an additional network hop between the server node handling the request and the primary owner of the requested entry. While this degradation could be significant for traditional caching workloads, it may be considered negligible for computation-heavy serverless functions. Figure 5 shows the impact of anchored keys compared to rebalancing based on the same scenario as above.
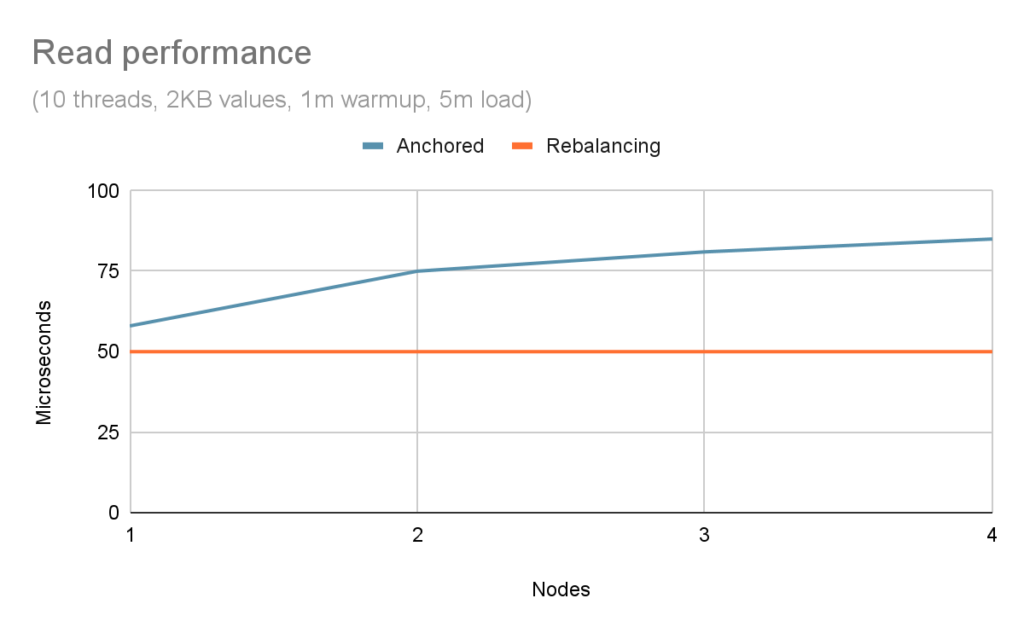
With a single node, the impact of looking up the ownership of an anchored key incurs a 16% penalty, which is negligible. However, as the size of the cluster increases, the requirement to forward the operation to a remote owner makes the penalty much larger.
Writes
The performance of writes shows the same progression as that of reads: as the size of the cluster increases, the round-robin algorithm has a decreasing chance of hitting the primary owner. The approach used by anchored keys, however, allows us to introduce a write-specific optimization to the load-balancing algorithm. Since entries are only written to the last node in the cluster, and clients receive an ordered list of server nodes, clients can send write requests to the owner directly. Figure 6 compares the performance of all three approaches.
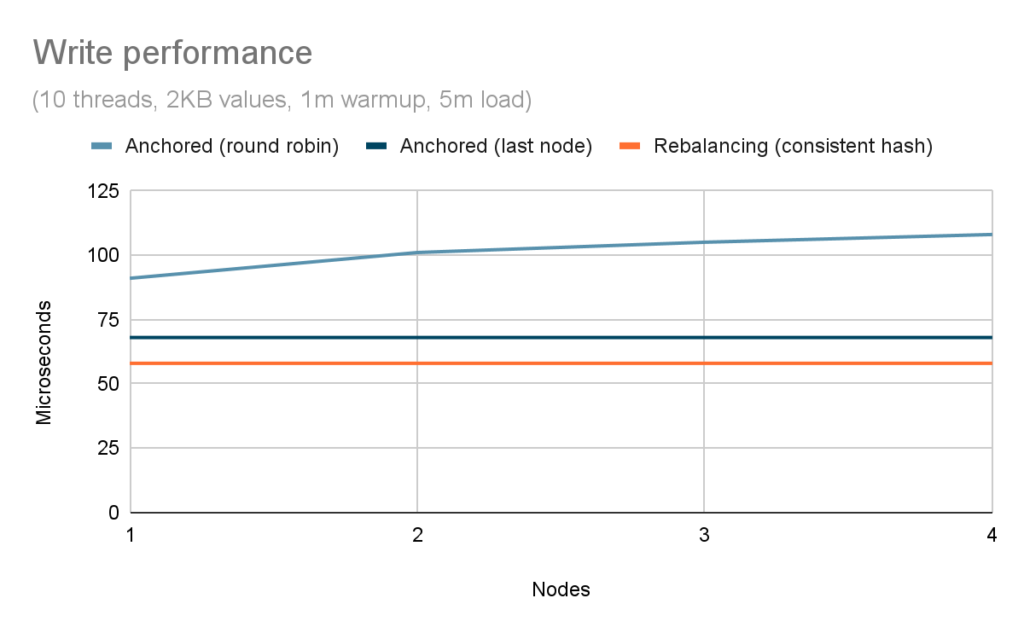
As expected, the round-robin algorithm suffers the same penalty as seen for the read scenario. The last-node approach, however, ensures linear performance comparable to the optimal consistent-hash algorithm. The impact of maintaining the additional key-to-node mapping makes writes 17% slower on average, which we believe is acceptable.
Anchored keys and serverless data analytics
The introduction of anchored keys to Infinispan has made it an ideal choice as a high-performance shared data store for serverless analytics, where scale-to-fit capacity is required to balance infrastructure costs with throughput and availability. Combined with the other components developed in the context of the CloudButton project, such as the Lithops multi-cloud framework and the Crucial Distributed Shared Objects library, it provides a compelling platform for a variety of use cases, including scientific scenarios such as metabolomics and geospatial analysis, as well as broader business scopes, such as diagnostic and predictive analytics.
To learn more about the CloudButton project, please visit the project homepage.

Funded by the European Union under Grant Agreement No. 825184. Views and opinions expressed are those of the author(s) only and do not necessarily reflect those of the European Union or European Research Executive Agency. Neither the European Union nor the granting authority can be held responsible for them.
Footnote
- See also D. Karger, E. Lehman, T. Leighton, M. Levine, D. Lewin, and R. Panigrahy. Consistent hashing and random trees: Distributed caching protocols for relieving hot spots on the world wide web. In Proceedings of the Twenty-ninth Annual ACM Symposium on Theory of Computing (STOC), pp. 654–663, 1997.