Understanding accuracy decay in online image retrieval systems within the context of open-set classification and unsupervised clustering
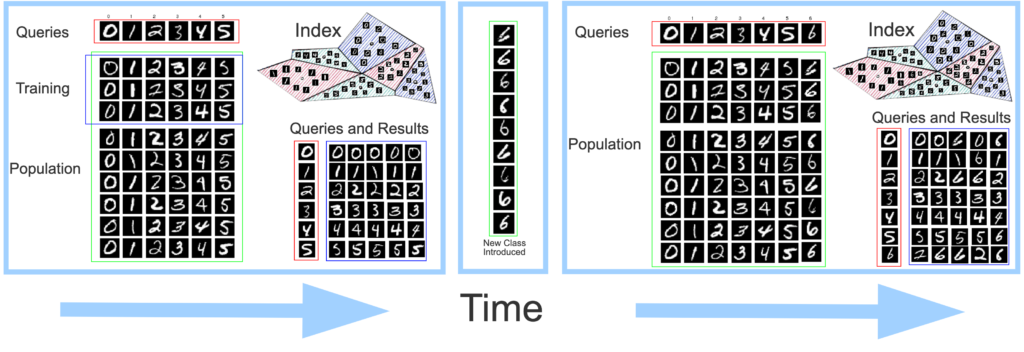
Image retrieval systems are extremely useful to political scientists and human rights advocates attempting to understand the scope and spread of disinformation in massive datasets. However, in standard image retrieval tasks the corpus of images is unchanging as time moves forward. When considering online disinformation this is clearly not the case. Image retrieval in an online system can essentially be modeled as an open-set problem, where there is no guarantee that the classes of images seen before will have any correspondence to the classes of images seen at present or in the future.
However the standard image retrieval indexing system is predicated on the fact that one can train on some representative subset of images to achieve a relatively accurate centroid representation of the underlying feature space consisting of all the images in the corpus. However as we move forward in time, using our model of the open-set nature of online image content, it seems intuitive that these centroids will, over time, become less representative of the image corpus as it continues to grow and change.
This raises several questions, which we shall study this summer:
1.) How quickly does this system decay and what might a reasonable re-training schedule look like, all while maintaining an acceptable retrieval accuracy?
2.) Does the feature type used have any effect on the retrieval accuracy decay?
3.) Does this decay happen across media other than images, such as text documents?
4.) Can we use techniques from distributed systems to help mitigate these problems? Can we approximate some idea of “load-balancing” for the underlying centroid space to help manage the appearance of new “classes”.
5.) Do the recent advances in unsupervised clustering, thanks to transformer-based methods such as DINO, help mitigate the problem as claimed? Or do their results on cold-data not translate well to the hot-data that one can expect to see in a live, online-scraping, system?
This is a summer sub-project of the Disinformation Detection at Scale project.