



The industry-academia collaboration aimed at using LLMs to help generate more secure code builds on its success to expand research into infrastructure.
In an era when software underpins everything from critical communications and global financial systems to lifesaving medical devices, security and reliability can never be an afterthought. Yet traditional development practices often leave gaps: vulnerabilities that can be exploited, costly to fix, or simply hard to detect until it’s too late.
These gaps were the motivation for SEMLA (Securing Enterprises via Machine-Learning-based Automation), a research initiative spearheaded by Prof. Marco Chiesa at KTH Royal Institute of Technology in Stockholm, Sweden, with support from industry partners including Red Hat, Research Institutes of Sweden (RISE), and Saab. Funded by Vinnova, Sweden’s innovation agency, between 2023 and 2025, SEMLA’s mission was to transform how secure software is built and maintained by harnessing the power of machine learning and AI.
SEMLA was an answer to a pressing question: Can AI help writing secure, resilient code, before vulnerabilities slip into production? The project takes aim at the critical but repetitive and error-prone tasks in software development that can lead to security flaws and operational risk. Instead of leaving these tasks solely in human hands, SEMLA blended machine learning with verification tools to automate analysis, detect vulnerabilities, and even assist in secure code generation.
The initiative revolves around three objectives: (i) rapidly learn about new and emerging software vulnerabilities, (ii) enable developers to generate secure code with AI assistance, and (iii) support the deployment of resilient systems and infrastructure. Through these goals, SEMLA aimed to embed secure practices throughout the software lifecycle with help of Generative AI.
Successful academic-industry collaboration
Projects like SEMLA thrive on cross-disciplinary collaboration. At KTH, computer science and security researchers bring academic rigor and experimental frameworks. Partners like RISE contribute domain expertise in systems and networking, while Sweden’s prominent defense and aerospace firm Saab introduces real-world use cases and challenging scenarios for networked software. As a global leader in open source enterprise platforms, Red Hat provides expertise in Linux and cloud-native systems and helps keep research grounded in industrial relevance. Thus one of my roles in SEMLA, as both a performance engineer and adjunct docent (associate professor), was to serve as a bridge between industry and academia, for example by helping demystify how Large Language Models (LLMs) can be applied to concrete challenges like network configuration and secure code generation.
The first outcome from SEMLA was featured in the Spring 2025 issue of RHRQ: NetConfEval, which was awarded the prestigious 2025 IRTF/IETF Applied Network Research Prize (ANRP),1 describes a benchmark that assesses how well different models translate high-level network policies into low-level, executable configurations. This is not just an academic experiment: network automation and eventual misconfiguration lead to severe, large-scale outages spanning large portions of the internet and security lapses. Frameworks like NetConfEval were an early attempt to demonstrate how LLMs could help pave the way for safer, more reliable infrastructure.
Continuing on this path, SEMLA published findings exploring the intersection of LLMs and software development, focused on the question of how AI can help generate verifiable code and analyze software vulnerabilities with minimal labeled data. As a result of this research, I have participated in the publication of two additional SEMLA papers. “Automating the detection of code vulnerabilities by analyzing GitHub issues” was presented at LLM4CODE 2025 (Ottawa, Canada), which runs in tandem with the IEEE/ACM International Conference on Software Engineering (ICSE). This led to the follow-up research paper “RAG against the machine: zero-shot software vulnerabilities classification using LLMs,” which will be presented at LLM4CODE 2026 (Rio de Janeiro, Brazil). In this article, I will discuss the research motivation and outcome of both papers.
Automating the detection of code vulnerabilities by analyzing GitHub issues
Software vulnerabilities—in simple terms, bugs that attackers can exploit—are a huge risk in modern codebases. This research investigates whether the bug reports developers write can be automatically analyzed to flag vulnerabilities before they become real security problems. Instead of scanning code itself, the authors look at natural language in issue titles, descriptions, and comments to see if an issue is about a security vulnerability.
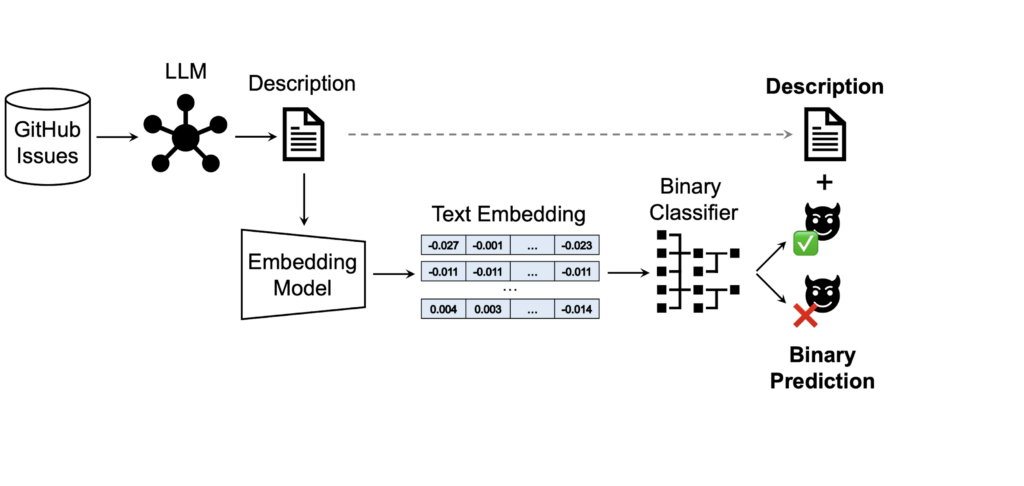
In Figure 1, the pipeline shows prompting of the LLM to describe and explain the input GitHub issue, the summary of the key details and the main problem discussed in the issue. This output is then converted into an embedding, which is fed into the classifier as input. The output is a boolean indicating whether the GitHub issue is a potential vulnerability (from the XGBoost classifier) and a detailed description (generated by the LLM).
Primary contributions
Building a dataset: SEMLA was the first to assemble a new dataset of GitHub issues annotated by whether they relate to vulnerabilities. We achieved this by filtering large numbers of issues and associating them with known vulnerability disclosures, which can be retrieved from public databases (e.g., the Common Vulnerabilities and Exposure [CVE] system maintained by MITRE), so the model can learn what vulnerability-related language looks like.
Applying Transformer-style models: The team was also the first, to our knowledge, to investigate the use of Transformer-based models (e.g., embeddings and LLMs like GPT) to classify an issue as either describing a vulnerability or not. The idea behind this approach is to let these models understand the text and context rather than use simple keyword matching.
Comparing classification approaches: We looked at embedding-based classifiers (embedding models + XGBoost), LLM-based classification, and combined pipelines that blend both semantic representations and model reasoning, using evaluation metrics like precision, recall, and F1 score (a balanced measure of precision and recall) to assess how well each approach separates vulnerability-related issues from normal bug reports.
Findings
Our comparisons demonstrated that models built on modern embeddings and machine learning perform significantly better than simple baselines. The combined approaches—for example, embeddings with boosted decision trees—generally give the best balance of detecting real vulnerabilities and avoiding false alarms. Some configurations achieve reasonably good precision and recall in distinguishing vulnerability discussions. (See “Automating the detection of code vulnerabilities by analyzing GitHub issues,” for details of these evaluations and analysis of the data.)
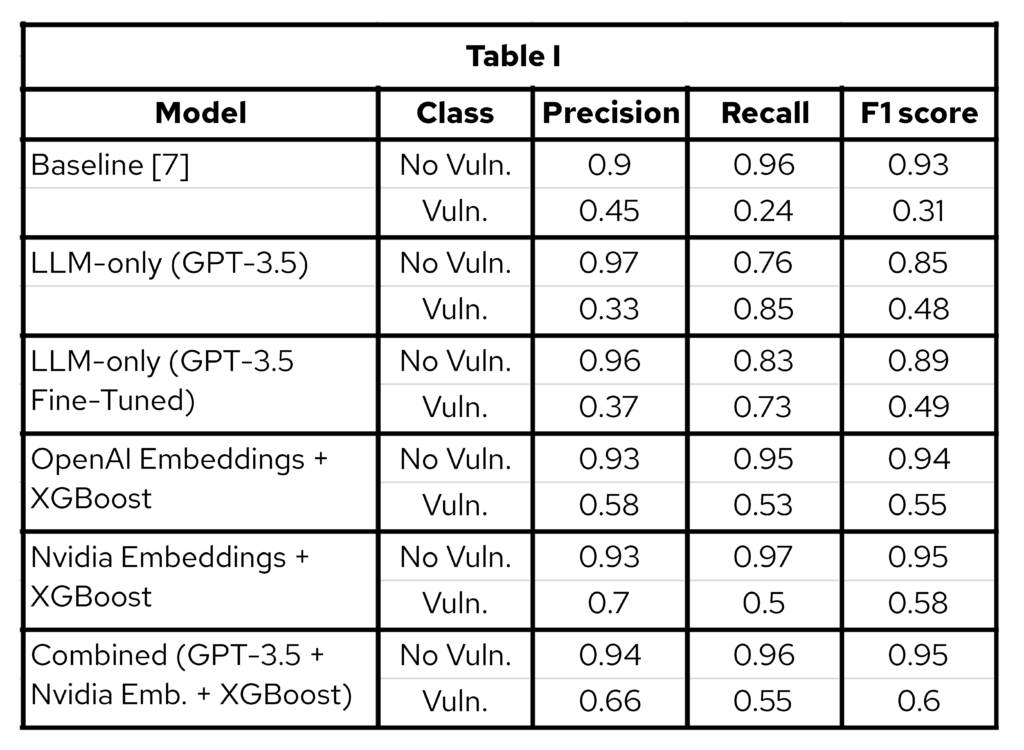
Table 1 reports precision, recall, and F1 score for the two classes of interest: Vuln. and No Vuln. Details on the dataset and training cutoff dates are in the paper. From this summary, we can derive two important conclusions.
First, transformer-based approaches outperform statistical methods. Our proposed approaches retain a higher F1 score, with the combined pipeline (last row of Table 1) performing roughly two times better in detecting vulnerabilities compared to the baseline. The results confirm our hypothesis that a Transformer-based approach is more capable of identifying vulnerabilities. Although the improvement in classification performance over the embedding-only model is moderate, this integration allows for more detailed analysis of the issues through embeddings.
Second, embedding models can detect vulnerabilities with high accuracy. Combining these embeddings with XGBoost resulted in high accuracy for detecting vulnerabilities (fourth and fifth rows). Surprisingly, the open source NV-Embed-v2 produced higher quality embeddings. This finding has several important implications: (i) it demonstrates that open source models can outperform proprietary ones; (ii) open source models are typically smaller, allowing deployment and execution on commodity hardware; and (iii) the overall pipeline remains efficient, as both the embedding model and XGBoost have significantly lower computational costs compared to LLMs.
Some limitations of this paper include reliance on how clearly developers describe security problems in natural language and the assumption that reported issues in public repositories follow certain practices (i.e., contain a consistent and high-quality level of technical details). In the next paper, we explore these limitations.
RAG against the machine: zero-shot software vulnerabilities classification using LLMs
The work builds upon the prior paper’s classification pipeline, which already showed that GitHub issues can be classified as vulnerability-related with high accuracy. The main contribution of this paper is to extend the pipeline beyond detection into formal vulnerability categorization, mapping issues to CWE (Common Weakness Enumerations) classes using Retrieval-Augmented Generation (RAG) rather than training large bespoke classifiers.

Referring to Figure 2, (1) is the preparation of CWE documentation. For each CWE entry, we retain its key fields, such as description, extended description, and examples. In (2), after some processing (split, alignment, and tagging) the CWE documentation is stored in a Faiss2 (Facebook AI similarity search) knowledge base. An initial LLM (3) filters out issues that are not associated with vulnerabilities.
Finally, the retrieved CWE candidates and their documentation are combined with the previously generated vulnerability description and (4) passed to an LLM using zero-shot prompting. The model reasons over this information to (5) determine the most suitable CWE label, without the need for task-specific examples.
Then, we ask whether LLMs combined with external knowledge retrieval can:
- Detect vulnerability-related GitHub issues
- Generate meaningful vulnerability descriptions
- Correctly categorize those vulnerabilities into CWE classes, all without fine-tuning, using only retrieval and prompting
This is important because CWE classification is hard: there are over 800 viable categories, the data is extremely sparse, and many CWEs are semantically adjacent.
Findings
Dense embedding retrieval is the dominant signal. Across experiments, embedding-based dense retrieval contributes the majority of categorization accuracy. Even without sophisticated RAG strategies or fine-tuning, dense retrieval consistently surfaces relevant CWE candidates. In other words, it implies that semantic similarity between vulnerability descriptions and CWE documentation is already enough to drastically reduce the search space.
LLM generation adds only marginal improvements. The LLM “reasoning” step slightly improves top-1 accuracy. In some cases, it introduces inconsistency or abstraction errors, especially when choosing between closely related CWEs, suggesting that RAG works well as a retrieval system, not as a reasoning system.
Top-K accuracy is more meaningful than strict top-1 accuracy. Because many CWEs are closely related, strict correctness can be misleading. The system often retrieves CWEs that are adjacent in the CWE hierarchy. When evaluated using top-5 or top-10 metrics, the system becomes practically useful for analyst-assisted categorization.
Crucially, it reframes LLMs as interfaces between unstructured human language and structured security knowledge.
No fine-tuning is required. All experiments are performed using off-the-shelf LLMs and open-source embedding models. Despite this, the approach reaches performance comparable to prior state-of-the-art systems that rely on heavy training or handcrafted features. Data sparsity and labeling noise remain limiting factors. It is likely that errors stem not from model failure, but from ambiguous GitHub issue descriptions, inconsistent or even incorrect CWE labels in the NVD, or semantic overlap between CWE entries themselves.
This research completes the loop started earlier by combining detection, summarization, and categorization into a single workflow. Crucially, it reframes LLMs as interfaces between unstructured human language and structured security knowledge.
SAFIR: the next steps
These papers demonstrate a machine-learning-driven framework and dataset for early classification of GitHub issues that are potentially relevant to vulnerability detection, effectively surfacing latent vulnerability signals from developer discussions before they are patched or logged in formal issues. Historically, the disclosure of CVEs takes a very long time, leaving systems potentially vulnerable for several weeks if not months.3
This line of work resides firmly within SEMLA’s vision of harnessing LLMs and transformers to automate traditionally labor-intensive and security-critical software engineering tasks. Beyond published conference papers, SEMLA continued until its end to seed additional academic outputs that explore LLM-driven code generation with formal verification—essentially trying to address the question of whether code generated by LLMs can be accepted as correct. More outcomes of the project in this line of investigation can be seen in the papers “Toward automated, contamination-free Dafny benchmark generation” (presented at Dafny workshop, colocated with POPL 2026 in Rennes, France) and “Dissect-and-restore: AI-based code verification with transient refactoring.”
Collectively, SEMLA’s research demonstrates (i) benchmarks for LLM applicability in structured engineering tasks, enabling reproducible evaluation across network and software domains, and (ii) frameworks that bridge machine learning model outputs with configuration synthesis and vulnerability insights, thereby reducing reliance on manual specification and oversight. Red Hat’s involvement in SEMLA highlights a broader journey: bringing human insight to AI-driven systems and using research to inform technology development and adoption and the people who build them. With the success story from SEMLA, we continued this journey with the newly funded project Secure AI for Intelligent Resilient and Confidentiality (SAFIR) project.
Following the successful collaboration with KTH Sweden, SAFIR will focus on the broader aspects of the next generation of secure, resilient digital infrastructure for AI and cloud-edge computing. In a nutshell, SAFIR will tackle one of the thorniest challenges of how to run sensitive AI workloads safely and reliably across complex distributed cloud systems.
SEMLA highlights a broader journey: bringing human insight to AI-driven systems and using research to inform technology development and adoption.
SAFIR focuses on two interlinked goals. The first is trusted execution: making sure AI applications can run on cloud and edge hardware without risking data leaks or tampering. That involves exploring confidential computing methods, where data stays protected even while being processed. The second is secure AI-driven orchestration: using machine learning itself to intelligently manage and automate how compute resources are allocated, how services recover from disruptions, and how the overall system anticipates shifting demands.
Again under KTH’s coordination, industry players like Ericsson, NVIDIA, Red Hat, Saab, and CanaryBit blend academic research with real-world system development. Beyond technical goals, SAFIR aims to enhance the trustworthiness and performance of cloud-edge application deployments so that critical sectors can adopt AI with more confidence. SAFIR runs from 2025 through 2028 with a multi-million-SEK (Swedish Kronor) budget acknowledging the excellence of the work already started in SEMLA and the real, pressing applications of this research in industry. Stay tuned!
Acknowledgments
I would like to thank the main contributors and head authors of the articles discussed: Edvin Nordqvist and Daniele Cipollone, master’s students at KTH Sweden. Papers mentioned in this article include the results of their work during their MSc theses at KTH, with collaboration from Red Hat.
Footnotes
1. Changjie Wang , Mariano Scazzariello, Alireza Farshi , Simone Ferlin, Dejan Kostic, Marco Chiesa (2025), “NetConfEval: Can LLMs Facilitate Network Configuration?”
2. Matthijs Douze, Alexandr Guzhva, Chengqi Deng, Jeff Johnson, Gergely Szilvasy, Pierre-Emmanuel Mazaré, Maria Lomeli, Lucas Hosseini, Hervé Jégou (2025), “The Faiss library.”
3. “Zero-day exploits surge, nearly 30% of flaws attacked before disclosure,” Infosecurity Magazine (22 Jan 2026).