



The networks that connect everything from cell phones to datacenters require frequent—and error-prone—human intervention for configuration. Recent research evaluates the effectiveness of applying various machine-learning models to the task.
Since 2023, Red Hat Research’s collaborative project Securing Enterprises via Machine-Learning-based Automation (SEMLA), in partnership with the Kungliga Tekniska Högskolan (KTH Royal Institute of Technology) in Sweden, has been exploring the potential of large language models (LLMs) to address network configuration challenges—for example to make them less prone to human errors.
This work led to the development of the first model-agnostic network configuration benchmark for LLMs: NetConfEval, which examines the effectiveness of different models by translating high-level policies, requirements, and descriptions specified in natural language into low-level network configuration in Python. Having such a benchmark is crucial for tracking the fast-paced evolution of LLMs and their applicability for networking use cases, as done for other tasks. This article presents insights gained from this research so far and future directions we plan to take.
Why is network configuration important?
Networks are the backbone of today’s communication infrastructure, powering everything from simple online interactions to mission-critical services. Network operators wield significant control over the flow of data in a network. These configurations—which can affect devices and services ranging from switches/routers, servers, network interfaces, network functions, and even GPU clusters—must be carefully configured to ensure the reliable transmission of information. Currently, network outages happen often, if not everyday. Network misconfiguration is among the common causes of unintentional outages, sometimes bringing down services for billions of users.
Although academia and industry widely adopted software-defined networking (SDN) to simplify network operation, network configuration still entails frequent human intervention, which is costly and difficult. It requires expert developers who are familiar with large and complex software documentation and API interfaces, as well as knowledge about libraries, protocols, and their potential vulnerabilities.
There have been many efforts to simplify this process by compiling a high-level policy specified by a network operator into a set of per-device network configurations and to minimize errors by generating configurations with provable guarantees via verification. Nevertheless, network configuration remains an arduous, complex, and expensive task for network operators because they must acquire proficiency in a new domain-specific language that may not be widely used and could potentially have flaws.
Leveraging LLMs for network configuration
While LLMs hold great potential for simplifying network configuration, there are a number of critical challenges that may hinder their widespread deployment. First, LLMs remain notoriously unreliable, producing outputs that may be completely incorrect, often called hallucinations. Second, reducing inaccuracies produced by LLMs highly depends on the way the user prompts the LLM, a concept known as prompt engineering. Third, operating or using LLMs is expensive: the cost of training, like fine-tuning an LLM such as GPT-4, may quickly grow to millions of dollars.
In NetConfEval, we highlight the potential benefits of using Natural Language Processing (NLP) and LLMs to address the following networking problems:
- Translating high-level requirements (expressed in natural language) into formal, structured, machine-readable specifications;
- Translating high-level requirements into API/function calls, which is particularly interesting for SDN and automation protocols in modern network equipment;
- Writing code to implement routing algorithms based on high-level descriptions;
- Generating detailed, device-compatible configuration for various routing protocols.
In this article, I focus only on Task 1 to demonstrate NetConfEval. Use cases 2-4 can be found in the original paper, “NetConfEval: Can LLMs facilitate network configuration?” by KTH authors Changjie Wang, Mariano Scazzariello, Dejan Kostic, and Marco Chiesa, with Alireza Farshin (NVIDIA) and Simone Ferlin (Red Hat). The paper was awarded the 2025 Applied Networking Research prize at the Internet Research Task Force open meeting in Bangkok. We discuss various opportunities to simplify and potentially automate the configuration of network devices based on human language prompts/inputs.
As an example, Figure 1 shows a sample input in high-level natural language, and its corresponding output in structured, low-level, formal language (Python).
Network components:
- 4 switches: s1, s2, s3, s4
- 2 end-hosts: h1, h2
Requirement set:
- All the switches can reach all the destination hosts.
- Traffic from s1 to h1 should travel across s2.
- The traffic from h1 to h2 is load balanced on 3 paths.
{
"reachability": {
"s1": ["h1", "h2"],
"s2": ["h1", "h2"],
"s3": ["h1", "h2"],
"s4": ["h1", "h2"]
},
"waypoint": {
["s1", "h1"]: ["s2"]
},
"loadbalancing": {
["h1", "h2"]: 3
}
}Figure 1. High-level requirements translated into formal, structured, machine-readable specifications
Depending on the complexity of the network requirements and policies, a network operator may directly add or remove new entries in the formal specification format, for example, to consider link preferences and/or resilience to more efficiently configure the network.
We devised an experiment as follows:
- Generate 3,200 network requirements focusing on reachability, waypoint, and load balancing, using Config2Spec1 on a topology composed of 33 routers;
- Randomly pick a certain number of requirements and slice them with various batch sizes2;
- For each batch, convert them into the expected formal specification format using a Python script;
- Transform them to natural language based on predefined templates;
- Ask an LLM to translate these requirements from natural language to the formal specification; and
- Evaluate the efficiency of different LLMs by comparing the translated version of formal specification with the expected one.
We evaluated different combinations of policies (e.g., Reachability, Reachability + Waypoint, and Reachability + Waypoint + Load Balancing). The batch size definition varies with the number of policies: for example, a batch size of 2 in the Reachability + Waypoint scenario indicates that the batch contains a Reachability and a Waypoint specification.
In our analysis, we use various OpenAI (GPT-3.5-Turbo, GPT-4, and GPT-4-Turbo) and Meta CodeLlama (7B-instruct and 13B-instruct) models, also fine-tuning GPT-3.5-Turbo5 and CodeLlama-7B-Instruct models with OpenAI’s dashboard and QLoRA. To this end, we created a dataset similar to the one used for the evaluation but with slightly different templates and then fine-tuned the models for three epochs.
Figure 2 shows the results of our analysis. GPT-4 performs similarly to GPT-4-Turbo3. It is important to find the appropriate batch size when translating high-level requirements into a formal specification format. GPT-4-Turbo achieves higher accuracy than GPT-3.5-Turbo and CodeLlama.
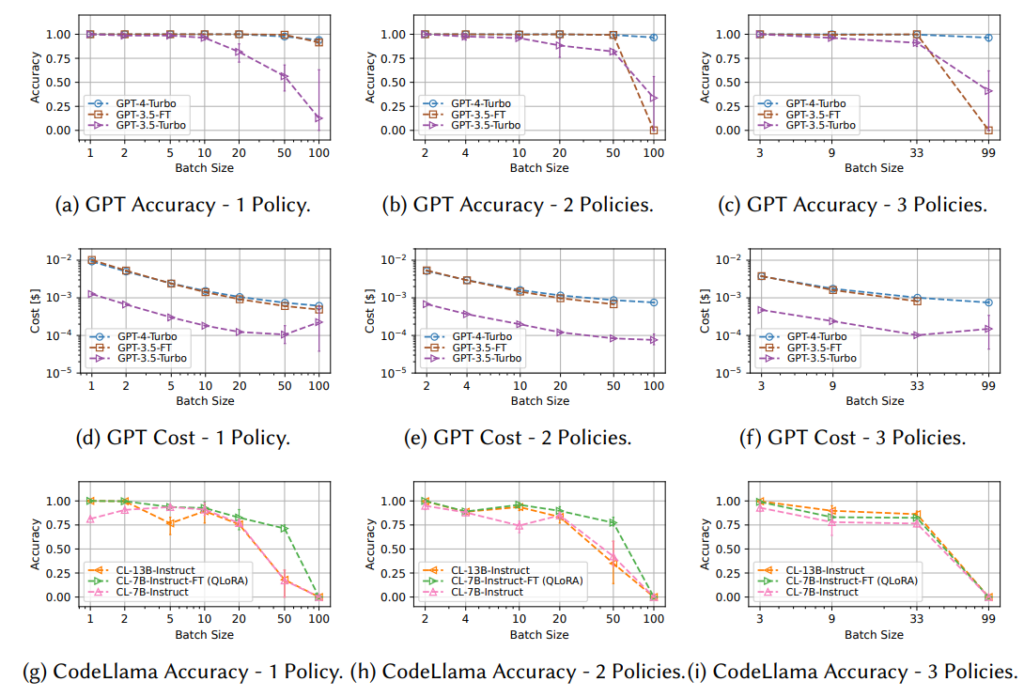
The results of our analysis demonstrate that:
Selecting the appropriate batch size is key for cost-effective and accurate translations. Since each inference request should contain preliminary instructions within the prompts, batching the translations could reduce the per-translation cost (prompts are conversation-wide instructions to the LLMs). Our results show that the accuracy of translations is worsened with larger batch sizes (especially for non-GPT-4 models). It is therefore important to carefully select a suitable batch size for each model to ensure the right trade-off between accuracy and cost. For instance, translating 20 requirements in one batch with GPT4-Turbo is around 10 times cheaper compared to translating 20 requirements one by one, while still achieving 100% accuracy (Figures 2a and 2d).
Context window matters. Translation accuracy decreases as we increase the batch size. We speculate that this reduction in accuracy may be related to reaching the context length (e.g., 4,096 maximum input/output tokens for all models except GPT-4-Turbo, which supports 128k input tokens). In most of the experiments, we noticed that the generated LLM outputs are always truncated when the batch size gets closer to 100.
Fine-tuning improves accuracy. Fine-tuning LLMs for a specific purpose could optimize their accuracy. While GPT-3.5-Turbo apparently performs worse than GPT-4-Turbo, Figures 2a, 2b, and 2c show that a fine-tuned version of GPT-3.5-Turbo achieves similar accuracy to GPT-4-Turbo, but with a higher cost, because OpenAI sets a higher per-token price for fine-tuned models. Figures 2g, 2h, and 2i show a similar takeaway for CodeLlama models, where fine-tuning the CodeLlama-7B-Instruct model using QLoRA can achieve better accuracy than the original model and sometimes better than the 13B-Instruct model.
GPT-4 beats the majority of existing models in our experiments. GPT models generally achieve higher accuracy than their open source counterparts (e.g., CodeLlama). We also experimented with other open source models (e.g., Mistral-7B-Instruct and Llama-2-Chat) and Google Bard7 , and they generated less accurate translations.

The ambiguity of human language and unfamiliarity with specific classes of problems may result in misinterpretations. Even when a single network operator is involved, contradictory network requirements can still occur, especially when the number of requirements is large.
Simple conflicts
A common case is two requirements that explicitly include contradictory information. For instance, a requirement specifies s1 to reach h2 while another requirement prevents s1 from reaching h2. To evaluate LLMs’ performance in conflict detection, we designed a set of experiments where we randomly selected one requirement from each batch, generated a conflicting requirement (e.g., the conflicting requirement of “h1 can reach h2” is “h1 cannot reach h2”), and inserted them back into the batch.
We evaluate the effectiveness of LLMs in detecting simple conflicts in two scenarios:
Detecting conflict as a separate step and explicitly asking an LLM to search for a conflict and report it
Asking the LLM to perform conflict detection during the translation of requirements into a formal specification format, a scenario we refer to as Combined
Figures 3a and 3b show the results of various GPT models when performing conflict detection. These results show that GPT-4 and GPT-4-Turbo reach almost 100% recall4 for different numbers of input requirements. These results suggest that such models are always capable of detecting conflicts when a batch contains a conflicting requirement (i.e., they do not report a false negative). Figure 3c demonstrates that conflict detection is much more accurate when done in isolation. As opposed to GPT-4 models, our results demonstrate a poor recall and F1-Score for GPT-3.5-Turbo model.
In order to determine whether this performance degradation is related to the smaller context window size of GPT-3.5-Turbo, we designed a new experiment to measure the impact of the position of a conflicting requirement in a batch: that is, to understand whether adding a conflicting requirement at the beginning, middle, or at the end could affect the accuracy of conflict detection. More specifically, we select a few batches with 33 requirements. For each requirement in the batch, we iterated through all the possible positions (indices), where we could insert a conflicting requirement.
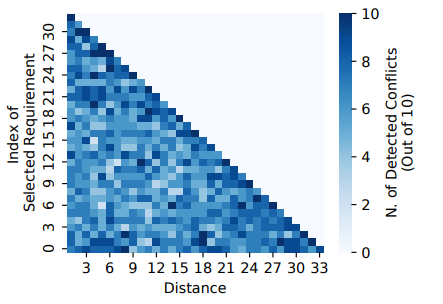
Figure 4 shows the number of conflicts detected out of 10 runs. One can observe that GPT-3.5-Turbo may be better at detecting conflicting requirements at the end of the batch: see the relatively darker squares at the hypotenuse of the heatmap. Finally, we compare the performance of GPT-4 when performing conflict detection separately and combined with translation (see Figure 3c).
Complex conflicts
An example of such conflicts is when a requirement specifies s1 to reach h2 through s2, while another requirement prevents s2 from reaching h2. We observed that most of the time GPT-4 translates these types of conflicts into Reachability and Waypoint specifications without reporting any conflicts, which is not desirable. To address this issue, we propose conducting intra-batch conflict detection before translating the requirements. If no conflict is identified within the batch, the translation results can be merged into the formal specification. Once the translation is completed, it is possible to use Satisfiability Modulo Theories (SMT) solvers to ensure there exists a solution for a given formal specification. In case of detecting any contradictions, an LLM can interpret them and provide feedback to network operators, which remains as our future work.
Takeaways
Our micro-benchmarking can be summarized into the following principles that could help network developers design LLM-based systems for network configuration:
Breaking tasks helps. Comparing the accuracy of conflict detection when a) performed as a separate task and b) performed during translation, we observe that separating the conflict detection and translation results in better accuracy (i.e., a higher F1-Score). This finding motivates the necessity of splitting complex tasks into multiple simpler steps and solving them separately.
Simple conflicts can be detected. GPT-4 and GPT-4-Turbo models are capable of successfully detecting all those simple conflicting requirements we presented to them.
Detected conflicts could be false positives. GPT-4 and GPT-4-Turbo sometimes report false positives (i.e., they detect a conflict when there is none). A concrete false positive example is “For traffic from Rotterdam to 100.0.4.0/24, it is required to pass through Basel, but also to be load-balanced across 3 paths which might not include Basel.” LLMs tend to overinterpret the conflict by, for example, considering Load Balance conflicting with Waypoints. It is, however, possible to minimize false positives by providing examples for possible conflicts in the input prompts.
Future work
Our main findings show that some LLMs are mature enough to automate simple interactions between users and network configuration systems. More specifically, GPT-4 exhibits extremely high levels of accuracy in translating human-language intents into formal specifications that can be fed into existing network configuration systems. Smaller models also exhibit good levels of accuracy, but only when these are fine-tuned on the specific tasks that need to be solved, thus requiring expertise in the specific tools and protocols that one expects to use.
For instance, LLMs can potentially simplify the cumbersome task of managing Kubernetes-based clusters, as these get larger and more distributed, or simplify network troubleshooting tasks. We also observed that finding the correct prompts is challenging and highly affects the results. We confirm that techniques based on step refinement5 are more effective also in tasks such as routing-based code generation. We observed that small models were ill-suited for code generation tasks, even those that were specifically fine-tuned on Python coding. We believe that fine-tuning models on network-related problems will not be sufficient, as network operators often need to write new functionalities that cannot easily be envisioned when fine-tuning the model (e.g., writing code based on new ideas from scientific papers, RFCs, etc.).
We hope that our work with NetConfEval motivates more research on employing AI techniques on network management tasks. Future iterations of our benchmark could a) enhance complexity by incorporating additional policies, implementing more sophisticated and distributed routing algorithms, and creating advanced configuration generation tasks and b) explore the impact of different task decomposition strategies or applying LLMs in network policy mining.
Footnotes
1. Rudiger Birkner, Dana Drachsler-Cohen, Laurent Vanbever, and Martin Vechev, “Config2Spec: Mining Network Specifications from Network Configurations.” In (2020) 17th USENIX Symposium on Networked Systems Design and Implementation, USENIX Association, Santa Clara, CA, 969-84.
2. We initialized the random function with a specific seed to ensure consistent results across various models.
3. We do not show the results for better visibility in the figures.
4. The recall metric reports the ratio of true positives (i.e., true positives divided by the true positives and false negatives).
5. Kumar Shridhar, Koustuv Sinha, Andrew Cohen, Tianlu Wang, Ping Yu, Ram Pasunuru, Mrinmaya Sachan, Jason Weston, and Asli Celikyilmaz, “The ART of LLM refinement: ask, refine, and trust.” 2023, arXiv:2311.07961.