Kernel Techniques to Optimize Memory Bandwidth with Predictable Latency
Over the past several years, memory bandwidth has become one of the most limiting factors on overall system performance. CPUs can execute dozens or even hundreds of instructions in the time it takes to fulfill a single memory load, resulting in suboptimal system performance. Designers addressed this by creating Non-Uniform Memory Access (NUMA) systems to limit the number of CPUs contending for the memory bus. NUMA systems are constructed of interconnected nodes, each of which includes local CPUs, memory, IO and node interconnecting logic. NUMA successfully limits the number of CPUs contending for the memory, but it also introduces multiple levels of memory bus bandwidth, depending on whether those CPUs are local or remote to the node’s memory. This requires both kernel and application level knowledge and implementation to optimize memory and therefore overall performance.
Designers also created multi-core CPUs and hyperthreading to keep processing hardware busy during excessive memory load times, combined with memory bandwidth throttling and monitoring to provide more predictable levels of service for individual processes. Hyperthreading shares the CPU execution and arithmetic logic units between two or more independent execution threads. Each hyperthread has its own private registers, so when one thread must stop for a memory load, the CPU can immediately switch to resume executing another thread. Hyperthreaded CPUs share internal caches and Translation Lookaside Buffers (TLBs), so switching between hyperthreads can easily result in excessive cache and TLB thrashing, and sometimes cache line and TLB invalidations. These effects can limit or even eliminate hyperthreading’s advantages. Memory bandwidth throttling attempts to limit how much of the overall memory bandwidth each core or hyperthread within a physical CPU can use, thereby guaranteeing some minimum level of service for other unlimited cores within the CPU. These CPU features also require both kernel and application level knowledge to maximize memory bandwidth while minimizing latency.
Recently, memory density has increased by orders of magnitude, thanks to Non-Volatile Dual In-Line Memory Modules (NVDIMMs). Modern NVDIMMs can be configured in both storage mode and memory mode. A system with NVDIMMs configured in storage mode contains both DRAM for main memory and NVDIMM for storage. A system with NVDIMMs in memory mode also contains both DRAM and NVDIMMs, but the DRAM acts as a totally transparent high-speed cache for the very large and dense NVDIMM memory. NVDIMM memory has much larger but also much slower write performance than DRAM memory. For this reason it’s very important that the DRAM successfully cache writes to NVDIMM memory. The caching scheme and logic used between the DRAM and NVDIMM memory also requires kernel knowledge to maximize memory bandwidth and minimize memory latency.
This project will conduct a full evaluation of memory bandwidth and latency for typical modern systems. This includes analyzing the individual components described above independently and also analysing how they interact with each other. We will explore how the Linux kernel can take advantage of the newest CPU hardware features and system memory topology. A significant amount of work has been done for NUMA placement in order to reduce remote memory access, but this work will likely be mutually exclusive with work necessary for proper scheduling of hyperthreads due to internal CPU cache and TLB conflicts. The use of NVDIMMs running in memory mode is the near term future of computers and must also be optimized. Currently the Linux kernel has no way of evenly distributing the pages of NVDIMM memory throughout the DRAM cache and this results in totally random memory bandwidth and latency. A technique known as page coloring will be investigated and evaluated.
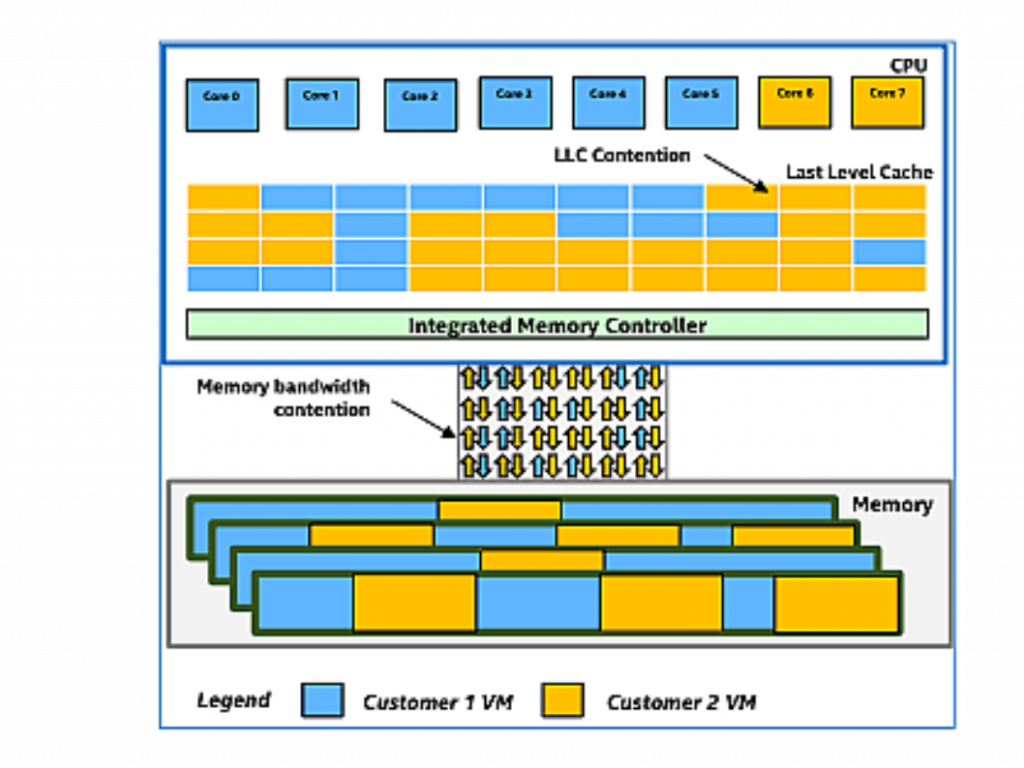
| Image from “Are Noisy Neighbors in Your Data Center Keeping You Up at Night?” Intel Cloud Technology, 2017 |
Project Poster

For more information on the unique partnership that produced this research, please see the website of the Red Hat Collaboratory at Boston University.