



Red Hat Research is participating in an initiative in the space of image disinformation detection, that is, determination of false information within images that are intended to mislead. The project began January 2021 in response to the need for more mature tooling in the fairly nascent space of image forensics and analysis using statistical and classical machine learning methods.
The project is a collaboration between Red Hat Research and the University of Notre Dame, led by Jason Schlessman on the Red Hat side and Professor Walter Scheirer, a member of UND’s Computer Vision Research Lab. The project has produced an open source Python toolkit and is in the process of assessing performance results using a ground-truth dataset.
The ubiquity of disinformation
Methods for detecting altered images are of particular interest, for many reasons. We live in an image driven world: the apps we use, the sites we browse, and, perhaps most importantly, the social media we engage are fundamentally image centric. This is not limited to static individual images; videos are sequences of images that have their own impact. Each of these sources serves myriad new images we then ingest and process. They have the power to leave a lasting impression on the viewer, which can then propagate rapidly among other individuals due to our society’s vast connectedness.
While this level of connectedness and data richness is of huge value to society, we cannot deny the potential for adversarial actors to take advantage of these influential information sources. Given the pervasiveness of image and video data, detecting the operations of these actors is a problem space whose pursuit offers benefits beyond technological progress, having impact legally, socially, and politically. A search for disinformation in a search engine or on a news site will find instances of convincingly altered images spreading as memes that have the potential to disrupt sociopolitical sentiment, from local elections to the Russian invasion of Ukraine.
We enjoyed a brief period when convincing alterations to images were possible only for those with digital art expertise. However, the same technological advances that provide the ability to manipulate images convincingly also make it easier for those without domain-specific prowess. We live in a deep fake world that brings these methods to the masses.
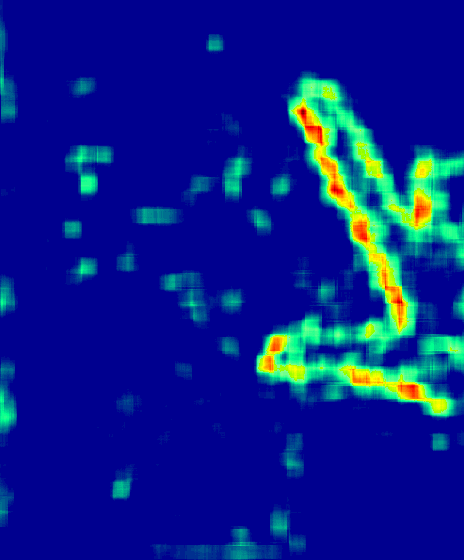
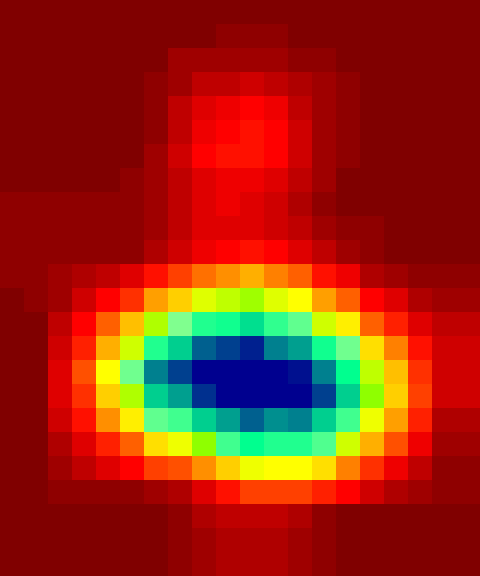

Finding a scalable solution
In the absence of reliable methods and tooling for detecting fakes, recognizing these images has required explicit one-off identification methods. As technologists, we believe it is imperative to help find efficient means of determining the provenance of images and thus the information they provide to the citizen internet user, as well as the technology executive, the journalist, or the data scientist.
When the Red Hat/UND collaborative effort began, the primary tool available for research beyond deep-learning approaches was a software library that was academic in nature. Meanwhile, Professor Scheirer and other researchers were in need of software development and repeatable workflows approaching the enterprise level Red Hat provides. The collaboration’s goals include providing image data security for all and acquiring input from both industry and academia; therefore, the efforts coming from this collaboration are open source and freely available.
A Python package providing an image manipulation toolkit, pyIFD was released publicly in August 2021. Since then, efforts have been made to assess the algorithmic performance of the methods provided in pyIFD with respect to deep-learning approaches, using a ground-truth image dataset. Results from these efforts will be published once complete. Ongoing work is underway regarding the real-time performance potential of these methods. We wish to determine if these methods could be deployed in a live system for immediate detection, aimed at all internet users. For example, could my phone give a warning for a suspect image, or must the detection occur on the server? If we do server-side analysis, given the number of images posted online daily, are the methods scalable?
Beyond this work, a member of Professor Scheirer’s lab, William Theisen, will conduct research at Red Hat as a summer 2022 intern. He will explore using multimodal detection methods for combating online disinformation at scale. This would specifically target images having text information (e.g., memes). Does this additional information lead to stronger detectors? Can their performance be achieved using off-the-shelf models on real data? Can this work keep up with the speed of information online? Stay tuned to find out!