



The competing demands of cost and performance make it challenging to optimize stream-processing applications. Current research is exploring new options.
Extracting value from streams of events generated by sensors and software has become key to the success of many important classes of applications. However, writing streaming data applications is not easy. Developers are confronted with major challenges, including processing events arriving at high rates, distributing processing over a set of heterogeneous platforms ranging from sensors to cloud servers, and meeting nonfunctional requirements such as energy, networking, security, and performance. The data within these applications can be largely dynamic, which requires the streaming system to adapt to ever-changing demands.
Stream-processing applications are commonly referred to as topologies. A topology consists of a set of stream-processing operations partitioned and deployed on available resources. The systems executing these partitions vary from low-power edge devices and sensors to virtual machines running in the cloud. This presents a challenge for the developer: how to partition the topology and how to make the best placement decisions.
An important aspect of this challenge is satisfying performance measures, particularly throughput and latency. When first deployed, a system might meet the desired performance criteria, but when the data it is processing changes, performance can suffer. Twitter is a good example: a major event occurring somewhere in the world can cause a large spike in traffic. Depending on the application, these data characteristics may be predictable, so the streaming topology could be modified in advance of peak load to satisfy the demand (e.g., during a US election). In other cases, the data rate may be more volatile, requiring a reactive approach.
Much of the existing research in this space aims to develop cost models to dynamically scale one or more of the partitions within a topology as the load increases, or to migrate partitions to increase resource utilization. However, we are interested in more complex adaptations to the streaming topology. If the network cost between two partitions is high but the processing required is low, is it possible to combine two partitions into one in real time? If the inverse is true, can we split one partition into multiple partitions? We describe these adaptations as operator fusion and operator fission, respectively.
A Functional Approach
Over the course of the research project, we developed StrIoT, a functional stream-processing system written in the Haskell programming language. The StrIoT library provides a set of stream-processing operators that can combine to create complex applications on streaming data. This includes definitions of operations commonly found among existing streaming systems, including Map, Filter, Window, and Combine style operations. Each of these functions was designed to be simple to use and understand, and they are easy to compose.
To provide a simple example, imagine a temperature sensor that generates a stream of type Int.
tempSensor :: Stream Int
Suppose that the only values of interest are those over 100. The application developer can define a function for this:
over100 :: EventFilter Int over100 temp = temp > 100
The stream can then be filtered:
streamFilter over100 tempSensor
The application developer may want to use 100 as the baseline temperature and represent all temperatures as their value over 100. To do this, the developer can define a function:
amountOver100 :: EventMap Int Int amountOver100 temp = temp - 100
Now, the developer can make a single application that combines both of these functions. The $ symbol is used in Haskell to chain functions so that the output of one becomes the input of another.
streamMap amountOver100
$ streamFilter over100 tempSensor
Each partition contains a set of one or more of these composed stream-operator functions and follows the architecture of a typical networked service. Figure 1 depicts a link-style partition, where events are arriving from an upstream partition and must be sent to a downstream partition post-processing. An input thread, running concurrently to the main execution thread performing the stream operators, processes these events. The events are decoded and input into a fixed-size queue ready for processing by the stream operator(s), then encoded before emitting downstream. The contents of each partition in this form are compiled like any other Haskell program.
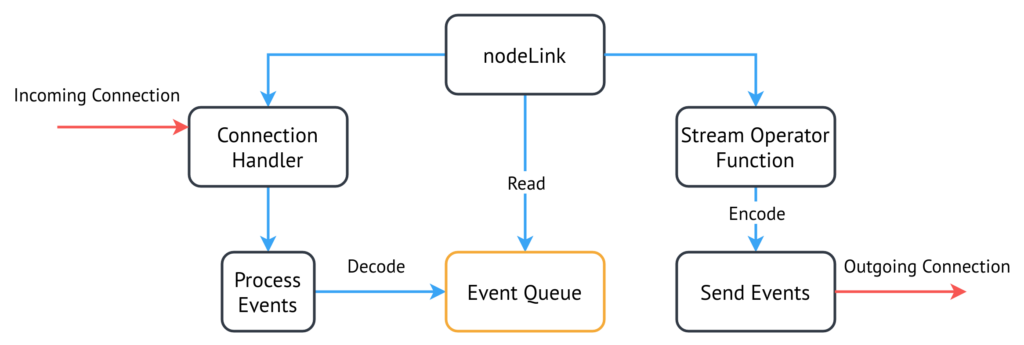
Figure 1. Partition internal architecture
Given that the template for each of the partitions is very similar, the deployment code is generalized to allow particulars of the operation to be determined at runtime. As each partition would likely be deployed in a container or onto a virtual machine, reading from environment variables is the most appropriate method of providing configuration to the application. The main benefit to this approach is that each partition of the streaming topology can be built ready for deployment without containing the networking configuration, which can instead be provided at runtime.
Deployment
We considered several different partition deployment methods during the development phase of the StrIoT system. These included the possibility of using cloud virtual machines and the use of serverless technologies, as well as the option of using containerization. We decided on containerization because containers allow a developer to encapsulate their application in a predefined environment. This environment contains all the dependencies required to run the application, and the images can be deployed on a variety of platforms without concern for the hardware specifics. This ensures that environmental conflicts do not occur from one user to another, and that the application conditions are reproducible. In the case of StrIoT, all of the build dependencies and tools required to build and compile a Haskell program are provisioned within the container. All of the packages that a standard partition requires are included in a base image. Then we extend the base image to include source code and any custom resources that a specific partition of the streaming system needs.
We chose Kubernetes as the means of deployment, as it provides a simple interface to deploy, scale, and manage containerized applications. The smallest possible set of one or more running containers for any deployed application is a pod. At runtime, the number of pod replicas can easily be changed. Kubernetes handles the creation and scheduling of new containers. When using Kubernetes as a platform for StrIoT, each partition of a topology is deployed as a separate application, and the individual pods are networked together. In this case, each pod consists of a single container with the same base control-flow behavior as shown in Figure 1, but with differing stream operators to match the partition.
Adaptivity
Previously, I introduced two complementary adaptations with differing benefits and costs: fusion and fission.
The main concern when performing either of these adaptations is ensuring that “effectively-once” processing is unaffected; i.e., that events are not duplicated, nor events lost, provided there are no failures. “Effectively-once” describes the effect of processing the stream and the expected output. If the adaptation results in sending the same event multiple times, duplicates must be filtered out before being processed so the application and result are the same as if the event were sent exactly once. Events cannot be lost; in the case of a missing event, it must be re-sent in the original sequence so it does not affect the expected result of the application.
Another issue to address is the stream-operator functions themselves: how will they behave and be affected by adaptations. Some of the stream-operator functions are classified as stateless functions, meaning the processing is performed on the current event and has no dependency on previous events. Other operators contain state that is used to compute the new values of the stream, which are classified as stateful operators. If a partition containing a stateful operator is the subject of an adaptivity operation, any state contained within the partition must be unaffected.
Fusion
In the fusion adaptation, two separate adjacent partitions are combined into a single partition, as shown in Figure 2.
Fusion results in a single partition that contains all the stream-operator functions that were in the original two partitions. The fusion adaptation requires a performance trade-off, and the benefits depend on the application in question. By fusing two partitions into one, we remove the boundary between partitions, resulting in reduced network transfer costs. The events do not need to be serialized/deserialized and sent between partitions over the network. However, fusion also results in reduced pipeline parallelism. Prior to adaptation, both partitions were processing events at different points in the stream simultaneously. However, the combined partition is only processing the most recent event received at the partition.
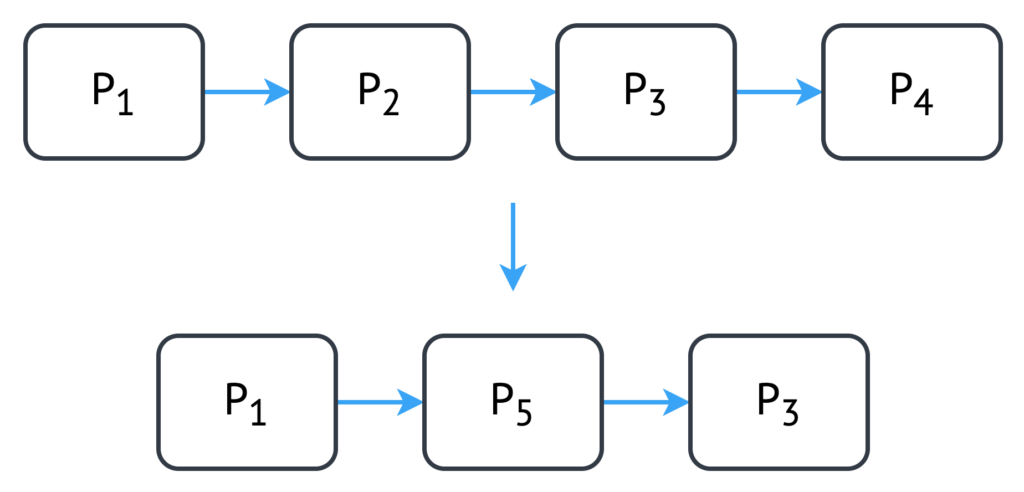
Figure 2. Partition internal architecture
Fission
The fission adaptation is the counterpart of fusion. In fission, the action of fusion is reversed: a single partition containing several stream-operator functions is split into two different partitions, each containing a subset of the original stream-operator functions (see Figure 3). The benefits and costs of fission are the inverse of fusion: potentially increased performance through pipeline parallelism, with additional network transfer costs due to an additional partition boundary.
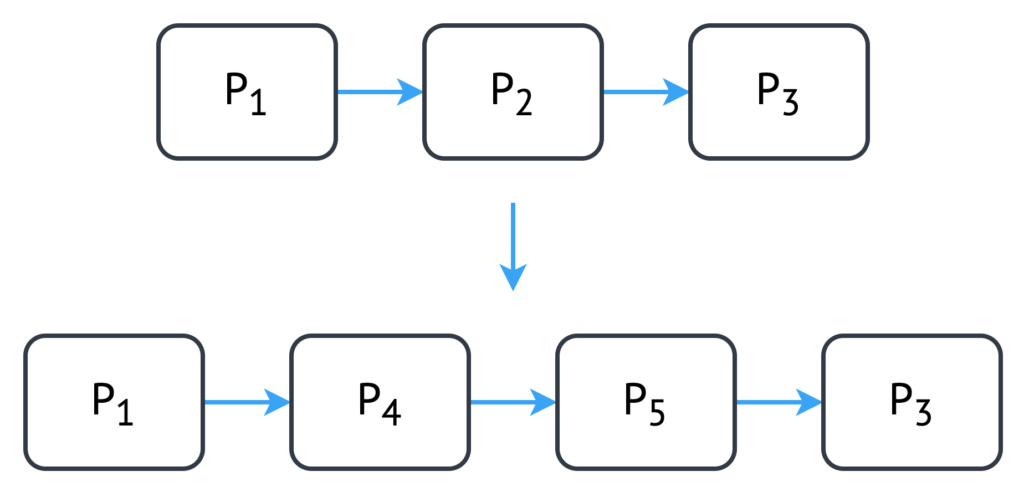
Figure 3. Partition internal architecture
Implementation
To ensure the ordering of events between partitions involved in adaptivity, we used Apache Kafka. Initially, Kafka was deployed standalone outside of a Kubernetes cluster. However, during an internship at Red Hat I discovered Strimzi, a Kubernetes operator that handles the deployment and management of Kafka resources. A Kubernetes operator (not to be confused with the StrIoT operator functions described above) is used to deploy and manage custom components within a Kubernetes cluster, typically automating the tasks that would be required of a cluster administrator. This allows the developer to submit custom resources to the cluster to be handled by the operator associated with the resource type. Strimzi simplifies the process of deploying Kafka brokers (alongside Apache Zookeeper) within the cluster. It can also be used to create, update, and delete KafkaTopic custom resources required for adaptation. The internship also prompted me to investigate the creation of a StrIoT Kubernetes operator that can handle the deployment of topologies and be used to trigger and manage adaptations.
As an example, the following code block represents a four-partition topology custom resource (this would look similar to the starting topology for fusion in Figure 2, with a Kafka topic as the connection channel between P₂ and P₃):
apiVersion: striot.org/v1alpha1
kind: Topology
metadata:
name: example-topology
spec:
partitions:
- id: 0
image: striot/striot-node-0:latest
connectType:
egress: "TCP"
edge: true
- id: 1
image: striot/striot-node-1:latest
connectType:
ingress: "TCP"
egress: "KAFKA"
edge: true
- id: 2
image: striot/striot-node-2:latest
connectType:
ingress: "KAFKA"
egress: "TCP"
edge: true
- id: 3
image: striot/striot-node-3:latest
connectType:
ingress: "TCP"
edge: false
order: [0,1,2,3]
The StrIoT Kubernetes operator handles the topology to create the deployments for each of the prebuilt partition images, providing environment variables for connection information. This allows the partition to read from the environment on startup and make connections to upstream and downstream partitions. In the case of Kafka connection types, the operator would interact with Strimzi to create a new KafkaTopic with a universally unique identifier (UUID) and pass the topic information to the relevant partitions. There is also an edge field, which the operator uses to apply NodeAffinity rules to ensure the container is placed on nodes within the cloud, or onto a small, low-powered edge device during experimentation.
The operator also triggers and manages the adaptivity itself. A management message is injected into the stream and passes through the partitions involved in adaptation. This triggers the partitions to acknowledge all messages up to this point in time and save any necessary state before safely shutting down. One or more new partitions are started and initialized with state in the case of stateful operator functions; they then resume from the same point in the stream. This results in a small pause in processing while transitioning to a more effective topology.
Next Steps
We have evaluated this system using a real-world data set, but there are two future research directions.
First, although we have implemented a set of adaptations, others should be investigated. While not discussed in this article, operator re-ordering is another option for adaptation. This requires prior knowledge of the processing within the operators and dependencies to ensure that application correctness is unaffected. A simple example is a map operation followed by a filter. If the filter is moved before the map, less data would need to be processed by the map. However, if the map modifies part of the data that the filter is dependent on, moving the filter first would result in different semantics.
Second, for the purposes of evaluation, the adaptations discussed in this article were triggered after a predetermined period of time. By using real-time metrics of the processing performance, the StrIoT operator should determine the most beneficial adaptations and perform them as necessary. The cost models must consider the performance of the operator functions themselves, the available resources on the devices present in the streaming system, and the metrics outlining topology performance.
Acknowledgments:
This work is undertaken within the Newcastle University Cloud Computing for Big Data, EPSRC, Centre for Doctoral Training (CDT) scheme, supported by Red Hat. Credit goes to Prof. Paul Watson (Newcastle University, UK) and Jonathan Dowland (Red Hat).