



Parallelism promises to make programs faster, yet it also opens many new pitfalls and makes testing programs much harder.
Anyone who has ever tried to write a piece of parallel software knows it is not an easy task. Parallelism promises to make programs faster, yet it also opens many new pitfalls and makes testing programs much harder. For example, writing and reading a variable in parallel from two threads may seem to work, but it will backfire sooner or later unless the variable is somehow protected by a lock or using some language primitives to make the accesses atomic.
The worst part about these problems is that they often manifest themselves only under specific timing of the involved threads or on a particular platform. Therefore, a program might run smoothly most of the time, but might fail once every few minutes or even once every few months. A service failing once every few months on a customer’s server is surely among developers’ worst nightmares. Knowing this problem exists, can we help developers find problems in parallel software?
We believe heavy-duty program analysis is one option that can help.
The problem
To meaningfully use parallelism, threads of a parallel program often need to communicate with each other. In this case, it is the responsibility of programmers to ensure that all of the communicating threads have a consistent view of the memory and therefore can work correctly. For example, consider an insertion to a doubly linked list. The thread that performs the insertion will create a new node, set its value, and set the pointers to the previous and next node inside the node-to-be-added. So far no problem can happen in parallel execution: the new node is not yet visible to the other threads, and it is not linked into the list.
However, consider that at this point another thread performs insertion to the same place in the linked list. Now the list has changed, but the pointers in the node-to-be-added do not reflect this change. If the node is inserted anyway, we will get an inconsistent list. We might miss some of the inserted elements when iterating over it, or even find different elements when iterating forward and when iterating backward. The root cause of this problem is that the addition of a node to the linked list is not an atomic operation. That is, it can be completed partially, and other threads might be affected by this partial result.
There is no single solution to our example problem. It might be possible to avoid accessing the list from multiple threads altogether. It might also be sufficient to add a lock that protects accesses to the list or to make the list use locks internally. Such locks will prevent two threads from inserting at once into the same list. It might also be necessary to design the whole program in such a way that it can use some high-performance lock-free data structures for the communication. In all but the first case, we are entering the realm of parallel programming, and we need to consider all its implications and risks.
One of the significant difficulties with parallel programs is that they are hard to test. This problem is caused by their dependence on timing. For example, our linked list example might work just fine if it so happened that the insertions are never executed at the same time during our testing. However, this does not mean that they cannot be executed at the same time. For this reason, tests might not fail for a buggy program, or they might fail only sometimes, making debugging harder. Therefore, there is a need for tools that can help test parallel programs.
Heavy-duty program analysis
Many techniques that can improve testing parallel programs have been introduced. They have a wide range of complexity: from relatively fast code-analysis techniques, similar to compiler warnings, to more involved techniques like various thread sanitizers that can detect unsynchronised access to the same memory region from multiple threads. At the far end of the spectrum, there are heavy-duty analyses that essentially explore all possible executions of the parallel program. While the first two categories are relatively simple to use by developers, heavy-duty tools are still mostly academic projects that come with specific limitations. However, we believe their promises should not be ignored, even if they are far from being silver bullets.
Heavy-duty tools promise to check that a program does not do anything wrong (e.g., trigger an assert, access freed memory) regardless of the timing of threads. They can also take into account more advanced behaviors of the system, for example, relaxed memory present in most contemporary processors. Automated heavy-duty tools do this using many different basic techniques, such as stateless model checking, explicit-state model checking, symbolic model checking, and symbolic execution. But in essence, they explore all the possibilities for the timing of threads that can lead to different outcomes. The main difference between these techniques is in their basic approach to the complexity of the analysis. Each of these techniques comes with their limitations, and it is important to keep in mind that they are trying to solve a problem that is probably not solvable for every case. There will always be programs for which tools will fail or require many more resources than available. There are also similar tools that can explore all behaviors of the program based on all its possible inputs, and tools that combine both capabilities.
The DIVINE analyzer
DIVINE is a modern, explicit-state model checker. Based on the LLVM toolchain, it can verify programs written in multiple real-world programming languages, including C and C++. The verification core is built on a foundation of high-performance algorithms and data structures, scaling all the way from a laptop to a high-end cluster. The name “LLVM” itself is not an acronym; it is the full name of the open source project (see llvm.org).
DIVINE is free software, distributed under the ISC licence (2-clause BSD). You can find more information about this project, download the software, or simply follow our progress at https://divine.fi.muni.cz/index.html.
DIVINE is one of the heavy-duty analysis tools that can be applied to parallel programs. It was developed in the Parallel and Distributed Systems Laboratory at the Faculty of Informatics at Masaryk University in Brno, Czech Republic. DIVINE specializes in analysis of programs written in C++ (and C) and can handle both sequential and parallel programs. It can detect various bugs including assertion violations, access out of memory bounds or to freed memory, use of uninitialized memory, and memory leaks.
To run DIVINE, it needs a test, and it can only detect problems that can happen in some execution of the test—i.e., it can try all possible ways that timing of threads and input data can influence the run of the test. This enables an entirely new way of writing tests of parallel programs. For example, instead of having to exercise the data structure with millions of elements inserted from several threads in the hope of triggering an elusive bug, it is sufficient to try it only with a few elements from two or three threads. DIVINE’s ability to explore all possible outcomes will mean such a test is sufficient (provided it exercises all features of the data structure, such as triggering growth in a test of a thread-safe hashset). Indeed, due to the computational complexity of program analysis, it is desirable to write tests for DIVINE that are as small as possible.
We will now look at some interesting recent additions to DIVINE with regards to parallel programs.
Relaxed Memory
In the struggle to construct more and more powerful processors, processor designers sometimes make decisions that make programmers’ lives harder. One of them is the use of relaxed memory to speed up memory access. Processors use caches, out-of-order execution, and speculative execution to mask the latency of the main memory. On most processor architectures, the presence of these mechanisms is observable by parallel programs. Maybe you have heard about the Meltdown and Spectre security vulnerabilities? They are caused by the same mechanisms that result in relaxed memory. While Meltdown and Spectre affect the security of programs and operating systems, relaxed memory affects only parallel programs, but can cause them to crash or produce incorrect results.
Relaxed memory manifests itself differently on different hardware platforms. For the sake of simplicity, we will consider the x86-64 processors manufactured by Intel and AMD. These processors power most modern laptops, desktops, and servers. Other processors, e.g. high-performance ARM, are often even more relaxed. On an x86-64 processor, when a program stores data to a certain memory location, the processor does not wait for the store to finish before it executes the next instruction. Instead, it saves the stored value and its address internally into a store buffer that holds it until the store is committed to the memory. If the same CPU core that saved it reads the given location, it will get the value from the store buffer. Therefore, single-threaded programs behave as expected. However, if the same location is accessed by another thread running on another core while the store is in the store buffer, the new value is not yet visible to the other thread.
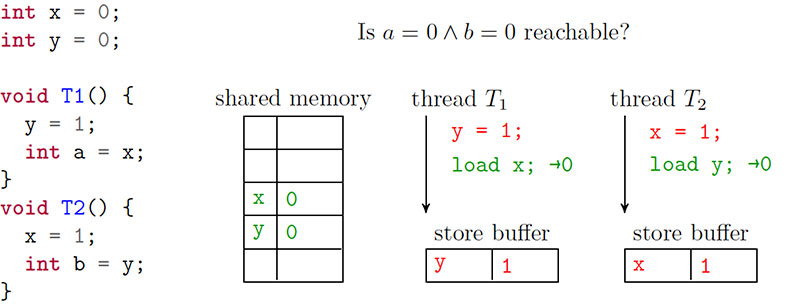
This can lead to very unintuitive behaviour. For example, consider a very simple program with two threads T1 and T2 and two global variables x and y (initialized to 0). Thread T1 performs two actions: it assigns 1 to x (x φ1) and reads y (read y). Thread T2 has the variables switched: it performs y φ 1 and reads y. The question is what happens if both reads can read 0?
If we tried simulating these threads, we would probably conclude this cannot happen. At least one of the assignments has to happen before both of the reads, and therefore at least one of the variables has to be 1. However, thanks to the store buffers, both reads can return 0 on x86-64. For example, we can first execute all actions of
T1 : x φ 1; read y, clearly, the read returns 0. However, on x86-64, it is now possible the value 1 for variable x is not yet saved in the memory but instead is in the store buffer corresponding to T1 .
Therefore the memory still contains value 0 for x. Now we execute T2 : y φ 1; read x. Unless the store x φ 1
was already propagated to the memory, the read would return 0: a value which seem to be impossible from the inspection of the program.
Figure 1 (below) shows the actions against the store buffers as described above.
Programs have to use some sort of synchronization to prevent relaxed behaviour from breaking their programs. One option is to use locks: locks not only prevent two parts of the program that use the same lock from running at the same time, but they also ensure that all modifications performed before a lock is released will be visible after it is acquired, even if each operation happens in different threads. However, locks can slow the program significantly, especially if they are used for long stretches of code or very often. An alternative approach is to use atomic accesses provided by the platform or programming language. These are faster than locks, but slower than unsynchronised access and can only operate on a single memory area of limited size (e.g., 8 bytes on 64-bit platforms). Atomic accesses are often used to implement high-performance thread-safe data structures that can be accessed from many threads at once. If the programmer chooses to use atomic accesses, they will have to consider the possible ordering of events very carefully and always keep in mind that it does not behave as expected.
Furthermore, testing program behaviour under relaxed memory is especially hard. Not only do we have all the problems already mentioned for parallel programs, but an improperly synchronised program can also be very susceptible to minor modifications. For example, a tool that tracks memory accesses to detect unsynchronised parallel access can also easily mask relaxed behaviour and related errors.
In 2018, we published an extension of DIVINE1 that allows it to analyze programs running under the x86-TSO memory model that describes relaxed behaviour of x86-64 processors and therefore should encompass behaviour of both current and future x86-64 processors. With this extension, DIVINE can find bugs caused by relaxed behaviour that would manifest on these processors.
While DIVINE is undoubtedly not the only tool that can analyze programs running under relaxed memory, we have shown that its performance is comparable to the best tools that handle x86-TSO and that each kind of tool seems to have different strengths and weaknesses (i.e. they can handle different kinds of programs well). We believe that DIVINE, with the wide range of bugs it can detect and with good support for C++, can be a useful tool for analysis of thread-safe data structures.
Detecting nonterminating parts of programs
Another interesting problem in parallel software is termination. It often happens that one action waits until the other finishes. For example, getting an element from a thread-safe queue might wait for an element to become available, or entering a critical section must wait until another thread leaves it. Furthermore, we are often not interested in termination of the whole program. It might be a daemon or server (or its event loop in the test).
Research in this area is much less intensive than in the case of relaxed memory. Most approaches to termination focus on sequential programs, or on specialized modeling languages for parallel programs. Even the approaches that target parallel programs in realistic programming languages are often focused on the termination of the whole program.
In 2019, we published a paper about an extension of DIVINE that allows it to find nonterminating parts of programs.2 To know which parts of the program must terminate, we use the notion of resource sections, essentially a piece of code with specified entry and exit points, such as a function or its part. With these resource sections marked in the program, the extended DIVINE can check that the program cannot get stuck inside any of these resource sections. Some resource sections can be marked automatically by DIVINE. These include waiting for locks, critical sections of locks, waiting for condition variables, and waiting for thread joins. The user is also able to insert new resource sections in their code by simple annotations. For example, an author of a thread-safe queue with a blocking dequeue operation might want to mark it as a resource section.
Where is DIVINE headed next?
Research around the DIVINE analyzer also focuses on other topics, currently mostly on a symbolic and abstract representation of data. This allows DIVINE to handle programs in which some variables have arbitrary values or some inputs contain arbitrary data. DIVINE can then decide if the program is correct for all possible values of such data. These kinds of analyses come with a significant increase in computational complexity, and some of the contemporary research in our group focuses on ways to improve its efficiency through the use of lossy abstractions and their iterative refinement. Further research in our group includes enabling the decompilation of x86-64 binaries into LLVM, which would allow DIVINE to analyze native binaries. There is also research on the use of symbolic data in decompilation. However, the research into decompilation is in quite early stages.
1 Vladimír Štill and Jiří Barnat, “Model Checking of C++ Programs Under the x86-TSO Memory Model,” DIVINE 4, divine.fi.muni.cz/2018/x86tso
2Štill and Barnat, “Local Nontermination Detection for Parallel C++ Programs,” DIVINE 4, divine.fi.muni.cz/2019/lnterm