Hybrid Cloud Caching
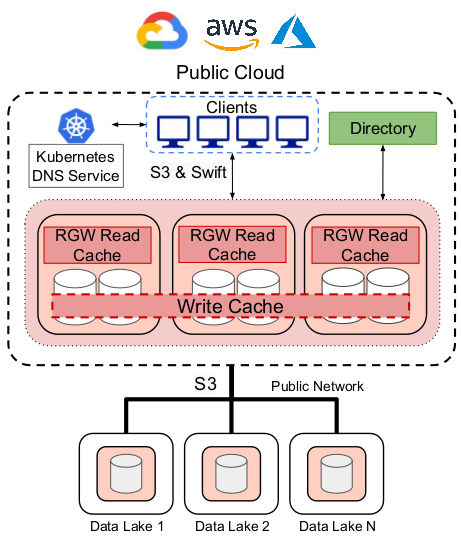
In this architecture, we use existing Ceph code to stand up a local Object Storage Device (OSD) cluster as a replicated durable write-back cache and Ceph’s RadosGateway (RGW) read cache in multiple public cloud regions. Clients can access data via S3 or Swift APIs. The architecture required no changes to client or server interfaces. Client requests are directed to the nearest cache instance via Kubernetes DNS’s service. Object metadata such as location, size, access frequency, and cache instance metadata such as the request load, and hit count are stored in a durable, fault-tolerant globally shared directory within the region. The directory allows us to do more flexible data placement and cache management. We deploy a Redis instance as a global directory. Cache architecture uses the S3 protocol to directly access the S3 supported data lakes (Ceph, HDFS, Amazon S3, Google Cloud Storage) and maps between S3 paths and the underlying objects.
A fundamental goal of the Hybrid Cloud Cache project is to allow simplified integration into existing data lakes, to enable caching to be transparently introduced into hybrid cloud computation, to support efficient caching of objects widely shared across clusters deployed by different organizations, and to avoid the complexity of managing a separate caching service on top of the data lake.
The values offered by public cloud services are clear for analytic workloads. Specialized hardware such as GPUs for doing artificial intelligence and machine learning computation may make more sense to effectively lease with operational funds when they are needed, rather than owning as under-utilized capital investments. However, lock-in and recurring expenses may make building large data sets inside public clouds unattractive compared to private infrastructure. These drivers are moving us towards a hybrid architecture where large data sets are built and maintained in private clouds, but compute/analytic clusters are spun up in public clouds to operate on these data sets.
Maintaining a hybrid architecture as described introduces challenges in optimizing the bandwidth and latency between the public cloud compute cluster and the private data lake. In this project, we design and implement a new hybrid cloud caching architecture to maximize throughput of these leased analytics clusters and avoid re-reading the same data from external private data lakes. Our solution enables users of Kubernetes clusters to easily access any S3 compatible data lake.
This project is a follow-on to the D3N project (Datacenter-scale Data Delivery Network): Caching for Datacenters and Data Lakes.