









A proposed Kubernetes scheduler plugin aims to introduce energy efficiency as a factor in dynamic scheduling while still meeting performance requirements.
Businesses in many sectors are setting aggressive sustainability goals, from transitioning to renewable energy sources to reducing existing consumption. Nowhere is the pressure to meet these goals more urgent than in the technology sector, where datacenters running AI workloads consume rapidly increasing amounts of electricity. Making those goals achievable requires greater visibility into energy usage and an intelligent way to adapt dynamically in response to changing requirements.
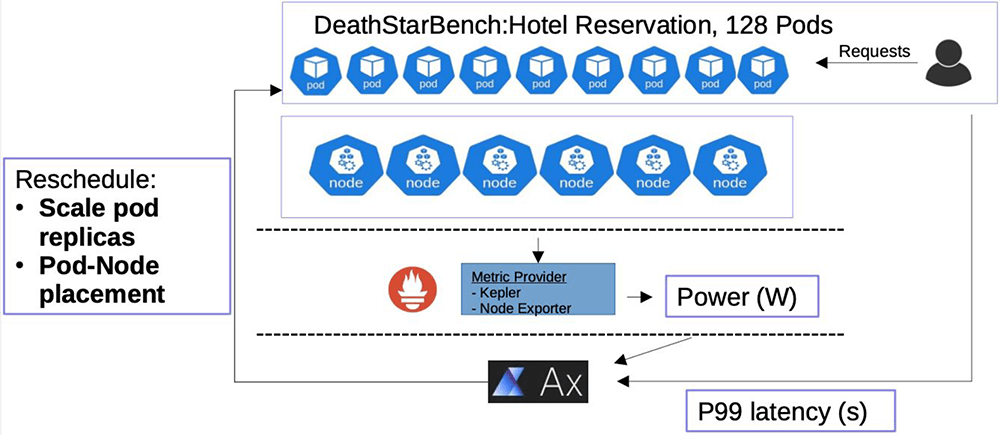
That’s the idea behind the Power Efficiency Aware Kubernetes Scheduler (PEAKS), a collaborative project involving engineers and researchers from Boston University, Red Hat, and IBM. PEAKS is a scheduler that can factor in sustainability goals such as power utilization. It uses observability metrics to schedule tasks on a Kubernetes or OpenShift cluster more optimally. For example, an AI training algorithm is a long-running job that can go over days to train a model, or it could even be a continuous process to keep retraining the model whenever new data is found. PEAKS can find the nodes best suited for a particular workload to meet the application performance goals while reducing overall energy consumption.
PEAKS origins
PEAKS uses insights from projects based in both industrial and academic research. The first is Kepler (Kubernetes-based Efficient Power Level Exporter), an open source project founded by Red Hat’s Office of the CTO, with early contributions from IBM Research and Intel. Kepler offers a way to estimate power consumption at the process, container, and Kubernetes pod levels. The second set of insights come from a constellation of projects based at the Red Hat Collaboratory at Boston University that apply machine learning to Linux kernel configurations to optimize performance and energy tradeoff, such as Automatic Configuration of Complex Hardware and Discovering Opportunities for Optimizing OpenShift Energy Consumption.
Kepler
Kepler utilizes a BPF program integrated into the kernel’s pathway to extract process-related resource utilization metrics. Kepler also collects real-time power consumption metrics from the node components by using various APIs or by using regression-based trained power models when no real-time power metrics are available in the system.
Once all the data are collected, Kepler can calculate the energy consumed by each process. It does this by dividing the power used by a given resource based on the ratio of the process and system resource utilization. Then Kepler aggregates the per-process energy consumption into totals for containers and Kubernetes pods. Data collected and estimated for the containers are then stored as time-series data in Prometheus.
Determining per-container energy consumption in a Kubernetes or OpenShift environment is a more difficult problem than it might seem at first glance. The way we proportion energy consumption is based not just on the computation for a given node. Many open source projects that report energy consumption give you only the dynamic energy consumption or the power you’ve consumed by running a computation. Kepler is following the greenhouse protocol, where you also must account for idle energy: the energy used for the maintenance of the nodes, such as cooling or just keeping those nodes alive. We do this by finding the idle energy of the whole node and distributing that evenly over all the containers. This is not strictly accurate, but it is a consistent basis using the best-case scenario.
Kepler also addresses the challenge of calculating energy consumption in a virtualized environment. It’s relatively easy to calculate the energy consumption of processes or containers running on bare metal, where there’s no abstraction. But in a virtualized and cloud environment such as AWS, you don’t know how many VMs are running on a host. That data may not even be available to you because there could be multiple isolated tenants running their VMs on a particular physical machine.
In the multitenant scenario, cloud providers don’t generally provide a solution. You must trust that AWS or Google report your total energy consumption not at the process level, but at the tenant level. In other words, they should report the total consumption of the server or servers hosting your processes, or the total consumption of a cluster that provides all your virtual nodes. There are certain hypervisors that can provide this data from their host machines, but most do not. If you’re running your workloads on the public cloud, most of the time you won’t have this information.
Kepler tackles this problem by using models for various CPU architectures. We created these models by running benchmarks on bare metal machines with various CPU architectures. Kepler uses these models to estimate the energy consumption of a virtual machine on a specific host based on the benchmarks for machines with the same CPU architecture. (For greater detail, read “Exploring Kepler’s potentials: unveiling cloud application power consumption” on the Cloud Native Computing Foundation blog.)
Dynamic tuning
Policies in the Linux kernel can enable it to run in a more energy-efficient manner. With literally thousands of tunable parameters, there are many options to push the energy efficiency of Linux, especially in the way it runs workloads. By replacing some of the default Linux hardware policies with policies that are specifically tuned for energy efficiency, we can save a lot of energy. However, we must also ensure that the policy balances energy efficiency with performance for running applications. Service Level Objectives (SLOs) specify these required performance bounds for a system. For example, an SLO could be set so that 99% of incoming requests to the kernel are satisfied within one-millisecond, which means we can exploit variations in this one millisecond range to maximize energy savings. As these requests come in, a properly tuned system can respond to them in a way that satisfies the one-millisecond SLO while also saving energy.
To accomplish this, we use a machine learning algorithm—in this case, Bayesian optimization. The algorithm learns about the behavior of the application that’s running and automatically tunes relevant kernel parameters to move towards that energy efficiency space. In testing with an assumed SLO of 99% response latency below 500 µs, we achieved energy savings of up to 50% compared to untuned default Linux. Even at a more stringent SLO of 99% latency below 200 µs, Bayesian optimization adapted to this performance requirement with up to 30% energy savings.
PEAKS
PEAKS is applying the same type of tuning techniques to scheduling. There are two main areas in scheduling to consider: pod placement and autoscaling.
Pod placement involves selecting the physical node where a particular pod will run. Not all applications require the latest and greatest hardware. In some cases, it might be even better to utilize older hardware due to its existing embodied carbon costs (the amount of greenhouse gas emissions associated with the upstream stages of a product’s life). Different generations of hardware (e.g., CPUs, GPUs) can have different Thermal Design Points (TDPs) due to their processor node technologies and other architectural characteristics. This is an interesting opportunity for tuning to maintain performance SLOs while slowly migrating functionality to older-generation hardware with drastically lower TDPs than the most recent versions.
Autoscaling involves determining the number of necessary pods to run as application needs change over time. The total number of pods can scale dynamically to meet SLOs as the workload changes. We can also leverage this information to improve energy efficiency. For example, if the load on datacenter servers follows a diurnal pattern, we may take advantage of this pattern to reduce energy consumption during periods of light load while still meeting performance goals.
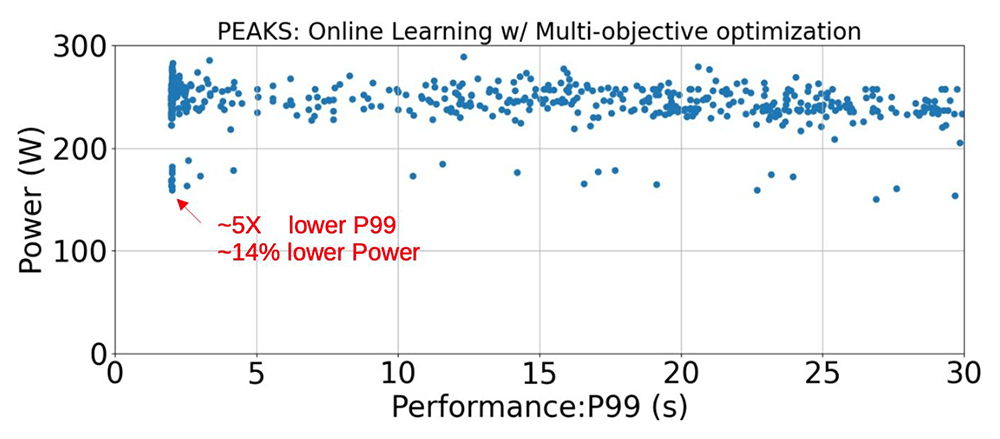
We take inspiration from the previous kernel tuning work to decompose the above scheduling problems into a set of machine learning problems.
To explore tuning for these scheduling aspects, we take inspiration from the previous kernel tuning work to decompose the above scheduling problems into a set of machine learning problems, using popular techniques including Bayesian Optimization, Bandit Optimization, Gradient Descent, and Simulated Annealing.
Future milestones and challenges
One of the biggest challenges we have had in the Kepler project is validating its metrics. This is a general problem in AI when using models: how can you stand by the accuracy of your estimations? That’s why we are running various benchmarks to validate the metrics on Kepler. If we know the metrics are off by a certain acceptable amount, we report that. One option we are exploring is using the power distribution unit (PDU) data from the Massachusetts Green High Performance Computing Center (MGHPCC) to verify whether the values measured by Kepler are comparable to measured power usage at the rack level.
In terms of kernel tuning, the next level to explore is how we can further tune the energy of jobs based on a varying abundance of green energy over time or location, or on the basis of cooling requirements. For example, we are investigating how kernel tuning could reduce carbon emissions from a refrigeration cooling system while also considering SLOs. Running jobs at night, when cooling needs are lower than during the day, might be an option for applications such as database backups, which must run daily but allow flexible scheduling.
You can learn more about PEAKS as a proposed Kubernetes scheduler plugin in the GitHub Kubernetes Enhancement Proposals (KEP) repository and in Han Dong’s PEAKS presentation at DevConf.US.