
Red Hat Research Quarterly
When is it secure enough? Vulnerability research and the future of vulnerability management
Red Hat Research Quarterly
When is it secure enough? Vulnerability research and the future of vulnerability management

Security researcher and professor Daniel Gruss is an internationally known authority on security vulnerabilities. Among the exploits he’s discovered with his research team are the Meltdown and Spectre bugs, and their software patch for Meltdown is now integrated into every operating system. Frequent collaborator Martin Schwarzl, a PhD student in Daniel’s CoreSec group at Graz […]
about the author

Vincent Danen
Vincent Danen lives in Canada and is the Vice President of Product Security at Red Hat. He joined Red Hat in 2009 and has been working in the security field, specifically around Linux, operating security, and vulnerability management, for over 20 years.
Article featured in


Red Hat Research Quarterly
November 2022
Security researcher and professor Daniel Gruss is an internationally known authority on security vulnerabilities. Among the exploits he’s discovered with his research team are the Meltdown and Spectre bugs, and their software patch for Meltdown is now integrated into every operating system. Frequent collaborator Martin Schwarzl, a PhD student in Daniel’s CoreSec group at Graz University of Technology (Austria), joined Daniel for an interview with Red Hat Vice President of Product Security Vincent Danen.
Vincent Danen: A lot of your research is on security-related topics. What got you interested in security in the first place, and why are you teaching it?
Daniel Gruss: At first, I was more interested in operating systems, and I wanted to continue teaching. I asked my professor, “Can I continue teaching?” He said, “No, that’s not possible. If you finish your master’s, you’ll go out into industry.” I said, “But there are these older people here, not much older than me. I don’t know what they are doing, but they still teach classes,” and he said, “Oh, you mean the PhD students?” And I was like, “Yeah, I think I could do that.”
He said that was the worst motivation to start a PhD he’d ever heard! But it worked out, and he became my PhD supervisor. That’s how I ended up teaching, and it’s also how I got into security, because that was the topic of the research group here. A coincidence, but I think it’s a very natural fit. If you have a background in operating systems, you have an easy time moving into systems security.
Vincent Danen: I agree with that a hundred percent. I built my own Linux distribution, and it teaches you a ton. I’d never dug into kernels before—that’s an eye opener! If you can do that, you can do anything. It really gives you a good understanding of the security side.
Daniel Gruss: Martin actually had a clearer vision that he wanted to go into security.
Martin Schwarzl: I attended a higher technical college with a focus on computer science, and I had a good teacher who was strongly encouraging students into security. We did a lot of Capture the Flag (CTF) playing and basic web stuff, and from there I fell into this rabbit hole where you get deeper and deeper and want to understand more and more things.
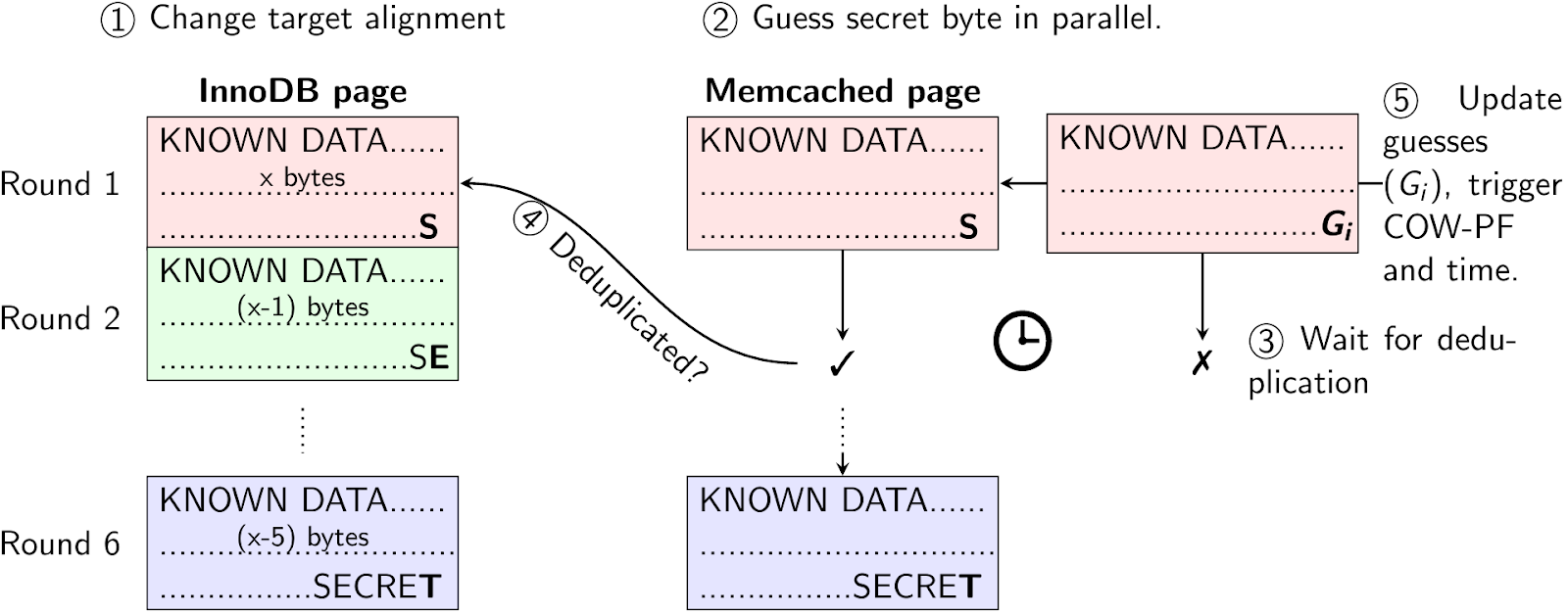
High-level conception of the InnoDB Reorganization attack. By exploiting the reorganization of data in InnoDB, the attacker can leak secret database data byte by byte.
Vincent Danen: A lot of your work is focused around hardware. Intel SGX work, AMD prefetch attacks, register abuses, memory deduplication attacks—all of it’s very hardware focused, which is different from a lot of other security researchers. What is it about hardware that interests you?
Daniel Gruss: I think the interesting part is the intersection. There are hardware-only security groups and software security groups, and our group is in the middle. For instance, if you take any application, there are multiple layers involved: You have timing differences caused by a hardware interrupt and also the operating system handling it. So you’re observing both of them. The general concept of “application” is implemented on the operating-system level. So you’re effectively combining different things, different layers, and suddenly you need some knowledge on all of those parts.
I think the interesting part is the intersection between hardware and software…
Martin Schwarzl: You also need to find applications that give you all the ingredients to perform these kinds of attacks. You start from the high-level application down to the operating system, down to the hardware. That makes it super interesting.
Vincent Danen: It makes it really random too, right? Because you have the differences in timing, whether it’s ARM architecture or the differences between Intel and AMD. Then you start throwing different hardware at it. Even if it’s the same version of the Linux kernel, maybe you’re throwing different processors in the mix. That adds a lot of interest to the problem, because now you’re looking at it from a whole bunch of different angles, but there are a lot more puzzles to solve.
Daniel Gruss: We’ve seen that, for instance, with the prefetch attacks on Intel and AMD. We published research on the attacks on Intel in 2016, and we published on AMD last year. There were five years between when we figured out prefetch attacks on Intel and when we successfully tried it on AMD! In that case, it turned out that the timings were inverted. The fastest case on Intel is actually the slowest case on AMD. Very curious, and not what we would’ve expected.
Vincent Danen: It makes you question every single assumption that you have.
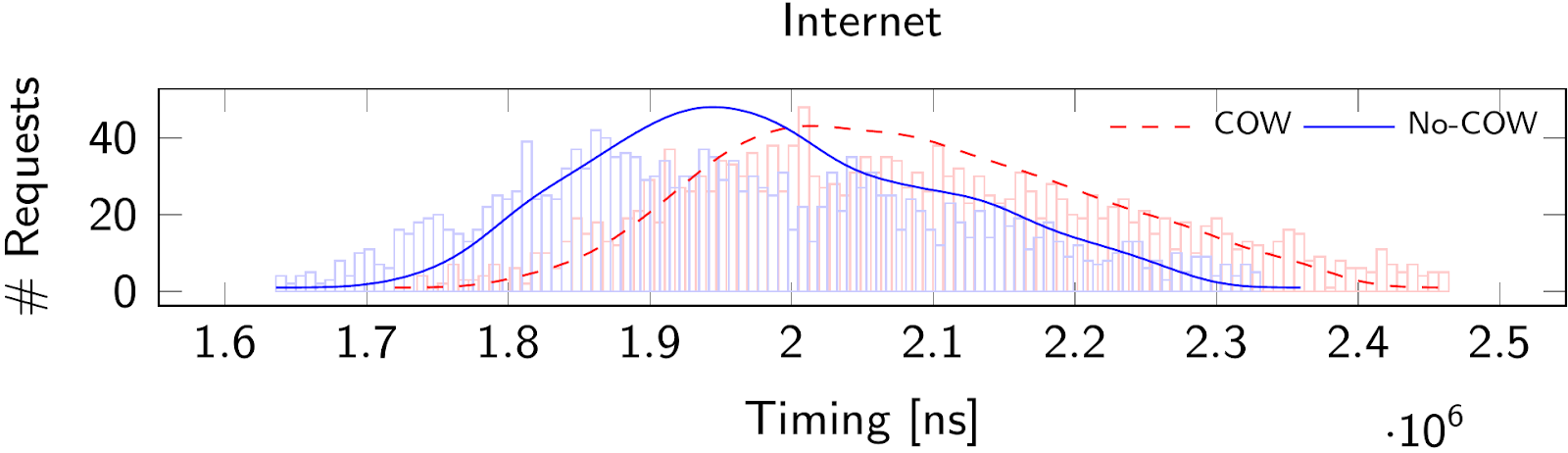
Histogram of network timings of a web server running memcached using a remote memory-deduplication attack with a 16-page amplification factor.
Daniel Gruss: Yes! I also like the insights we gained from the Platypus paper about this ability to perform a power side channel attack from software. Because power side channel attacks are super powerful—in theory, there’s nothing you can do to defend against them. Even if you try something complex, like masking on the hardware—which is super popular—even if you can perform a super fine-grained measurement on a specific point, you can still break up those schemes. That’s why people say, “Okay, let’s not just mask it one time, let’s split it up further.” The idea is that if we split it up often enough, an attack takes so much time, and it’s so expensive, that it’s not worth it.
But there’s no ultimate security, which makes it difficult sometimes to determine whether what you’ve done is good enough. And it’s difficult to convince other people that what you’re doing is good enough, because there’s never 100% security.
Vincent Danen: I wish more people understood that. Because you get a lot of people who assume, “Oh, there’s a vulnerability. We have to fix it.” But sometimes the benefit you get from exploiting that vulnerability is so small, while the expense to fix it is so high, that you just think, why are we worried about this? It makes me think of some of the Spectre and Meltdown stuff and some of the mitigations to prevent it, for example, turning off hyperthreading.
Daniel Gruss: Yes, but that’s a bit dangerous too. We’ve seen a similar effect with the COVID situation, where everybody got the vaccine then said, “Oh, COVID wasn’t so bad. We could have skipped all of this.” The question is, was it not so bad because of the vaccine? Or was it not so bad regardless of the vaccine?
Likewise, we don’t know what would have happened if we hadn’t had the Meltdown and Spectre patches. For Meltdown, I’m absolutely sure we would’ve seen exploits in the wild. It was just not interesting anymore because the systems were all patched rather quickly. For Spectre, it’s super tricky. Spectre is far more tricky to exploit than Meltdown.
But there’s no ultimate security, which makes it difficult to determine whether what you’ve done is good enough.
Martin Schwarzl: In some cases, especially when it’s inside the same process, it’s difficult to fix these optimizations because you lose plenty of performance, and that’s the opposite of what you usually want.
Vincent Danen: That’s really important—there’s that middle ground you want to hit. You don’t want to go to either extreme, either: “Don’t bother patching it because performance is king and that’s all I care about,” or, on the other side, “I don’t care about performance. I want perfect security,” which, as you say, doesn’t exist, and you’re going to lose all of the performance for the sake of a false sense of security.
The middle ground is somewhere in between, where you can get a decent amount of performance and a decent amount of security.
It all depends on your risk appetite and what it is that you’re willing to sacrifice.
Daniel Gruss: I think this direction will be even more relevant in the near future, because we are running into a global climate and energy crisis. We have exponential growth in energy consumption, and at some point people will start asking, “Why do we run this security feature again? Can’t we just turn it off?” Why do we have these patches installed? How much do they cost? We don’t know how much they cost. We are not measuring it.
Vincent Danen: That is an interesting point. If you do all of the security mitigations and you’re increasing power consumption, what does that do for the overall global footprint of that cost? When the benefit of what you’re defending against is not worth that expense…
Daniel Gruss: Exactly.
Vincent Danen: … then we have to revisit our assumptions.
Daniel Gruss: Yes. That’s absolutely the direction we will pursue in the future: policies with a more fine-grained selection for which workload gets which security level and which types of protection, and do that on a workload basis, on a computer basis, on a user basis. Do I share the cache? Do I not share the cache?
Vincent Danen: That really speaks to knowing your environment, right? You don’t need to put in the same security mitigation in a development environment versus a production environment. And even in a production environment, it depends on the type of data you’re dealing with.
That’s absolutely the direction we will pursue in the future: policies with a more fine-grained selection for which workload gets which security level
Daniel Gruss: Right—and also on the exposure of the system. Is it possible for an attacker to run a binary on that system? If that’s not possible, I can rule out a lot of attacks already.
Vincent Danen: It really requires the end user to understand what they’re doing with their devices. Right now, I don’t feel like most people do. They just assume they’re running a computer, and since they care about security, they have to have all the security, patches, mitigations, and so on in place, but they don’t know if those things are useful or valuable. So I like this kind of capabilities view, because I think it’s going to become really important.
Another question I had was about the complexity of the research you’re doing. A lot of it is very complicated, and some of it is probably very difficult to prove. You can theorize it, and then you have to go out to find it. How long does it typically take to theorize and then test for those vulnerabilities?
Daniel Gruss: I would say that we build up a lot of theories and like 90% or maybe 95% of them just don’t work. We try them, and then we realize, “Oh, it doesn’t behave that way.” The remaining maybe 5% that we pursue, some of them turn out to work in the direction we thought they would, but they’re not exploitable, so they’re not interesting for our purposes. We learn something about the system, but nothing we want to investigate further or publish about.
And then there’s a very small percentage left over where we can say, “Oh, that’s, that’s so interesting!” We can evaluate the security implications of this effect and publicly document it.
Vincent Danen: When 95% don’t work, how much time do you spend before you decide you’ve reached the point of diminishing returns?
Daniel Gruss: That’s an excellent question. There is no algorithm you can follow to tell you to spend one more week on something. There’s nothing except your intuition, your gut feeling basically, which is tricky.
It also changes over time. When I was getting my PhD, I was rather efficient. When I run experiments now, I’m much slower, because I have so many more concerns: “Oh, but what if this goes wrong? And what if this goes wrong? And have you considered this?” There are many things to think about, and you can lose a lot of time even before you start experimenting. It’s not so much about, “Should I invest one more week?” It’s that you bring your big backpack of thoughts.
So you lose efficiency over time, but you also build up more and more knowledge, which helps your intuition on whether you should invest more time in something.
Vincent Danen: That’s the importance of experience. I was going to ask Martin about this, too, since you are earlier in your career. From the perspective of the teacher, maybe there’s more caution, and then there’s the student who’s doing the research, who is—I don’t want to say reckless, but a little bit more…
Daniel Gruss: … let’s say, optimistic?
Martin Schwarzl: That depends on the topic. How well started is something you are trying to do new research on? If you have something like cache attacks, where there is 15 years worth of research already, and you want to build upon it, you can count on certain things. But if you go into a completely new direction that no one has any idea about, it takes a few months to get in touch with the topics.
And another piece is, of course, luck on the hardware you’re running the stuff on.
Daniel Gruss: For example, there was an article by Anders Fogh that basically described Meltdown, but it didn’t work. The Meltdown attack that works is essentially the same. It’s on a different machine, and the code we had looked a bit different, but the idea is the same, and it works.
Vincent Danen: Was it due to access or lack of access to the particular hardware?
Daniel Gruss: I worked with Anders before on the prefetch side channel attack, and the laptop he most likely tried it on was one he also used during the prefetch side channel attack paper. I suspect that the laptop just has a very, very short transient execution window. And that means you don’t have much time to read the data, encode it, and then leak it on the other side. So yes, hardware makes a big difference. One person in our group always had luck with his laptops. We had so many attacks that we tried on different laptops, and usually if he’d started something, you’d hear, “Oh, it worked!” Then someone else tries on their laptop, and nothing works.
Vincent Danen: It’s almost infuriating. That dependency is really hardware based, not just on the chip, not just the CPU, but all of the other pieces and combinations of pieces.
Daniel Gruss: Yes! But then that’s the next step that we take. We need to figure out why it doesn’t work on other machines and how we can make it work.
Martin Schwarzl: Can we talk about the ÆPIC leak? So we were doing research in a completely different direction. We were trying to understand the Intel microcode on these Goldmont devices.
Daniel Gruss: I was very skeptical. I didn’t think there was anything in that direction that would be publishable.
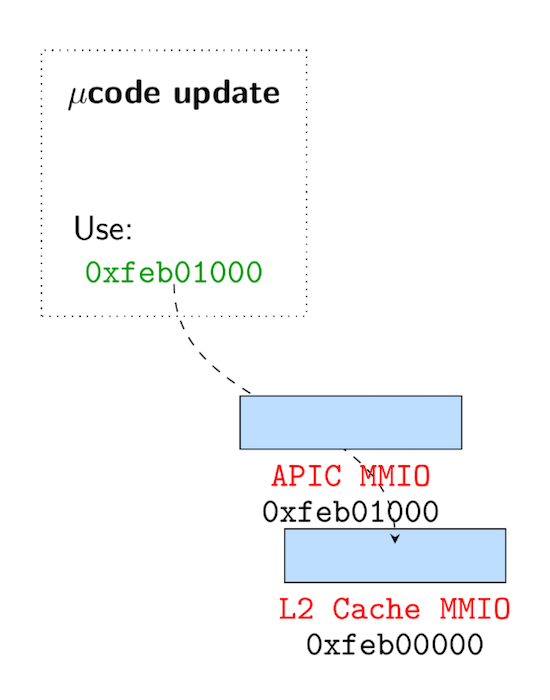
Failed exploit attempt to leak the µcode update. By leveraging the memory sinkhole, an attacker tries to leak the full microcode during an update.
Martin Schwarzl: And then we somehow had the idea to use the memory sinkhole and read from the APIC to sample data during a microcode output. During the reverse engineering, we saw in the decompiled microcode that a special physical page is used during the update routine. We wanted to read out the plain microcode update, but it still did not work. Then my colleague Pietro did that on every single machine in our lab. There was exactly one device where we actually read some data, and it was this notebook we got as a gift from Intel.
From there, we started doing more research and found the ÆPIC leak.
It was completely lucky that we had the device there, because if we didn’t, we might have decided it’s just not exploitable. We tried 15 different devices that did not work, but on the sixteenth one it did.
Vincent Danen: So there’s luck, but there’s also tenacity. And in your case, there’s the availability of hardware.
Martin Schwarzl: Also, you need this drive to always look for the needle in the haystack. If you don’t have the stamina, you will probably stop after one or two days.
Daniel Gruss: People often start a topic and then, after a few days, say, “Ah, there’s nothing there.” But did you try this? No. Or this? No.
So there’s luck, but there’s also tenacity.
Vincent Danen: You have to exhaust all the possibilities, right? One of the other things I wanted to ask you about was your involvement in patching and fixing vulnerabilities. A lot of times, finders of vulnerabilities are just there to break things, not necessarily to fix things. But you take this other approach, where you are also instrumental in fixing things, due to your understanding and the research that you’ve done.
How receptive are vendors to that? When you reach out and say, “Hey, we found something,” what does that look like?
Daniel Gruss: So there are researchers from industry and researchers from academia, and there may be differences. In academia, it’s now expected that you propose some defenses or mitigations in your publication. That’s why we start thinking about defenses while working on these publications. Sometimes if an idea is strong enough to be a publication by itself, we also publish it separately. And we constantly try to stay in touch with the vendors. With all of these microarchitecture vulnerabilities, that’s primarily the CPU vendors, but often enough also software.
In general, they really like to hear from us. They don’t necessarily want to share ahead of time what they are planning to do, but even that sometimes works. We had some very successful collaborations with Red Hat, where we worked on mitigations together. But, for instance, on the Intel side, we sometimes got microcode before it was released. Not in all cases—for instance, for ÆPIC, we had to wait until everyone got it. Of course, it would be interesting, because then we can look at it earlier and see whether it works. There have been cases where we couldn’t tell them in time. If we get the microcode patch and the disclosure is one week later, we need some time to test it.
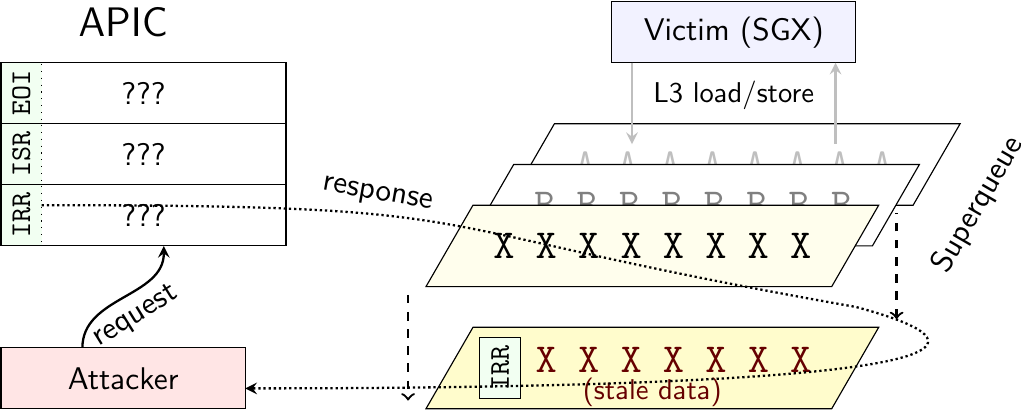
ÆPIC LEAK: On most 10th-, 11th-, and 12th-generation Intel CPUs, the APIC MMIO undefined range incorrectly returns stale data from the cache hierarchy. This attack can be used to extract arbitrary data from SGX enclaves, such as cryptographic keys.
Vincent Danen: Given how expensive it is to release a patch, particularly when it comes to hardware, you’d think they’d want you to look at it. Because that’s not an easy thing to deploy—all these different microcode and firmware updates and whatnot. If you have somebody willing to test this on your behalf for nothing, other than just time and accessibility, you would think, “Hey, these guys broke it. Let’s give them something and see if they can still break it or if this fix actually works as we think it will.”
Daniel Gruss: Yes, although the “for free” part is a bit tricky. The researchers are not free on my side! Intel has funded my research group in the past, and I’m very happy that we also have this collaboration with Red Hat. That currently helps me to stay above water.
Vincent Danen: That’s a really good point. So Daniel, you’re a researcher, you’re a teacher, and in the security field, in particular, we hear a lot about burnout and rising rates of burnout for security professionals. Here you are, a security professional and a security teacher, so given that risk of burnout, how do you deal with work-life balance? And how do you set an example of work-life balance for your students? Because I think that’s part of teaching as well.
Daniel Gruss: That’s tricky. If the funding situation is good—and it has been good in my group for some time—that helps. If you have projects where the project work is for publications or working on mitigations that you can then publish, that’s perfect.
When the funding situation is more difficult, you have to pick up more of those projects where you have to invest a lot of time on deliverables. And for the PhD students, that is a time where you’re also studying, and there’s a bit of variance in how intensive this is for you, how motivating, or how frustrating.
The middle ground is somewhere in between, where you can get a decent amount of performance and a decent amount of security.
For me, the PhD, although I was working a lot, was the best time of my life. Even though I had a lot of teaching and a lot of other stuff, it was what I wanted to do. I picked my own research topics. I could focus on that research. I could publish it. I had a lot of freedom, and I enjoyed that freedom. It depends on how much energy you can draw out of that. Right now, I don’t manage to stay within healthy working hours because there’s too much project work to do <laughs>.
Vincent Danen: But if you enjoy it, I think there’s that passion part. If you’re passionate about the work and you get energy from it. I think sometimes that tips the scales a little bit, right?
Martin Schwarzl: Most of the time, you’re focusing on a thing you want to do or getting things done so that you can work on new stuff. I think during COVID times, it was demotivating, because usually as a reward for your work you can go to conferences at nice locations and have another one or two weeks of vacation afterward to celebrate or relax after your heavy workload.
That was completely gone, so you just had the standard work, the project work, the teaching, of course, supervising bachelor’s and master’s students. You’re still working the same amount, but the motivation of knowing that once you get this thing accepted you can go somewhere was gone.
Daniel Gruss: Yes. We were at conferences last week, and it was so good to be at conferences again. I hope we get a bit more of that now.
Vincent Danen: Agreed.
On that note, thank you for taking some time from your busy schedule to share your thoughts with us today. This has been awesome.
SHARE THIS ARTICLE
More like this
The conversation around AI in higher education sometimes feels stuck in abstraction. When industry and academia work together, however, that conversation is immediately grounded in things like the transition to data-driven engineering, the necessity of academic agility, and the hard work of building infrastructure that is reliable, auditable, and open. North Carolina State University Provost […]
Dan Alistarh is a humble guy. The ISTA (Institute of Science and Technology, Austria) professor and founding employee of Neural Magic (the startup Red Hat acquired by Red Hat in 2025) isn’t one to brag, but fortunately we called in his former postdoc advisor, MIT professor and Neural Magic cofounder Nir Shavit, to really draw […]
Ask Gen AI to design a CIO action figure, and you might get a guy in a dark suit with a briefcase and laptop as accessories. That won’t give you an accurate idea of Boston University CIO Chris Sedore, who’s held the post at Syracuse University, University of Texas at Austin, and Tufts University. You […]
The name Luke Hinds is well known in the open source security community. During his time as Distinguished Engineer and Security Engineering Lead for the Office of the CTO Red Hat, he acted as a security advisor to multiple open source organizations, worked with MIT Lincoln Laboratory to build Keylime, and created Sigstore, a wildly […]
“How many lives am I impacting?” That’s the question that set Akash Srivastava, Founding Manager of the Red Hat AI Innovation Team, on a path to developing the end-to-end open source LLM customization project known as InstructLab. A principal investigator (PI) at the MIT-IBM Watson AI Lab since 2019, Akash has a long professional history […]
John Goodhue has perspective. He was there at the birth of the internet and the development of the BBN Butterfly supercomputer, and now he’s a leader in one of the toughest challenges of the current age of technology—sustainable computing. Comparisons abound: one report says carbon emissions from cloud computing equal or exceed emissions from all […]
What if there were an open source web-based computing platform that not only accelerates the time it takes to share and analyze life-saving radiological data, but also allows for collaborative and novel research on this data, all hosted on a public cloud to democratize access? In 2018, Red Hat and Boston Children’s Hospital announced a […]