Research Days US 2020
Series of virtual conversations about research & innovations in open source
Research Day US 2020 was the first-ever virtual event organized by Red Hat Research. This time expanded to a series of unique conversations between researchers and Red Hat experts. Did you miss live stream? Watch recordings online!
#RHResearch
That is a wrap!
Research Days US 2020 has come to an end, but the inspiring content doesn’t stop there.
In these four series, we had 15 sessions and conversations delivered by 15 Red Hat experts and 22 researchers from Harvard, Yale, Boston University, and other leading universities who discussed and explored research to improve privacy and security, make experimentation and system execution more reproducible, and enhance the performance of cloud systems.
Thank you to all the attendees and speakers who made Research Days US 2020 a success! Missed the conference? No need to miss out. All the session recordings are available on demand now.
Research Days US 2020 Digital Illustrations
Some of the sessions were accompanied by amazing designers and illustrators: Máirín Duffy and Madeline Peck from Red Hat, and Andrew Federman from Collective Next who visually captured all of the key points of talks and discussions. Check them out:


Meet the Speakers
PARUL SOHAL
Boston University
>Visit profile
JOSE RENAU
University of California, Santa Cruz | CROSS
>Visit profile
CARLOS MALTZAHN
University of California, Santa Cruz | CROSS
>Visit profile
ADAM SMITH
Boston University
>Visit profile
SAHIL TIKALE
Boston University
>Visit profile
RICHARD HABEEB
Yale
>Visit profile
KARSTEN WADE
(Conversation Leader)
Red Hat
>Visit profile
JIŘÍ BENC
(Conversation Leader)
Red Hat
>Visit profile
WILLIAM HENRY
(Conversation Leader)
Red Hat
>Visit profile
GAGAN KUMAR
(Conversation Leader)
Red Hat
>Visit profile
ALI RAZA
Boston University
>Visit profile
KATE SAENKO
Boston University
>Visit profile
ILYA BALDIN
University of North Carolina | RENCI
>Visit profile
FREDERICK JANSEN
Boston University
>Visit profile
BENJAMIN BERG
Carnegie Mellon University
>Visit profile
HAO CHEN
Yale
>Visit profile
SHERARD GRIFFIN
(Conversation Leader)
Red Hat
>Visit profile
MIKE BURSELL
(Conversation Leader)
Red Hat
>Visit profile
BILL GRAY
(Conversation Leader)
Red Hat
>Visit profile
MARZIYEH NOURIAN
North Carolina State University
>Visit profile
JASON ANDERSON
University of Chicago
>Visit profile
JAMES HONAKER
Harvard University | Facebook
>Visit profile
BAISHAKHI RAY
Columbia University
>Visit profile
MOR HARCHOL BALTER
Carnegie Mellon University
>Visit profile
RICHARD W.M. JONES
(Conversation Leader)
Red Hat
>Visit profile
JUANA NAKFOUR
(Conversation Leader)
Red Hat
>Visit profile
JAYASHREE RAMANATHAN
(Conversation Leader)
Red Hat
>Visit profile
DOUGLAS SHAKSHOBER
(Conversation Leader)
Red Hat
>Visit profile
MICHELA BECCHI
North Carolina State University
>Visit profile
IVO JIMENEZ
University of California, Santa Cruz | CROSS
>Visit profile
MERCÈ CROSAS
Harvard University
>Visit profile
APOORVE MOHAN
Northeastern University
>Visit profile
ZHONG SHAO
Yale
>Visit profile
AHMED SANNAULAH
(Conversation Leader)
Red Hat
>Visit profile
CHRIS WRIGHT
(Conversation Leader)
Red Hat
>Visit profile
BANDAN DAS
(Conversation Leader)
Red Hat
>Visit profile
NATHANIEL MCCALLUM
(Conversation Leader)
Red Hat
>Visit profile
Program Comittee
ORRAN KRIEGER
Boston University
>Visit profile
ULRICH DREPPER
Red Hat
>Visit profile
SANJAY ARORA
Red Hat
>Visit profile
Research Days US 2020 Agenda
Each Research Day started with a networking session from 11:00 AM – 12:00 PM (EDT) followed by the main program: conversations between academia researchers and Red Hat experts (12:00 – 2:00 PM). Similarly, there was afternoon networking sessions after the full day of talks (conversations) starting at 2:00 pm and ending at 3:00 pm (EDT).
Kernel/Hardware Development
Sep 9
11:00 AM - 12:00 PM (EDT)
NETWORKING
11:50 AM - 12:00 PM (EDT)
Introduction from Research Director
by Hugh Brock
12:00 - 12:30 PM (EDT)
Kernel Techniques to Optimize Memory Bandwidth with Predictable Latency*
Speaker: Parul Sohal, Boston University
Conversation Leader from Red Hat: Richard W.M. Jones
Show the abstract
Consolidating multiple applications on the same multi-core platform while preserving their performance is of the utmost importance in real-time systems. A similar problem has emerged in cloud computing systems. Meeting SLAs requires isolating the performance of primary workloads from co-located noisy neighbors. Lack of performance isolation arises due to contention over shared memory resources, such as last-level cache space, main memory bandwidth, and DRAM banks. Hardware vendors like Intel have started introducing techniques like Resource Director Technology (RDT) to manage shared memory resources. In the context of RDT, a promising feature is Memory Bandwidth Allocation (MBA).
In this presentation, we study whether MBA is capable of providing strong isolation via main memory bandwidth management. In doing so, we make a series of surprising discoveries. Come to the presentation to have a look at these and see joint management of main memory and LLC bandwidth by combining MBA and budget-based regulation.
12:30 - 1:00 PM (EDT)
Unikernel
Speaker: Ali Raza, Boston University
Conversation Leader from Red Hat: Richard W.M. Jones
Show the abstract
Unikernels are small, lightweight, single address space operating systems with the kernel included as a library within the application. Because unikernels run a single application, there is no sharing or competition for resources among different applications, improving performance and security. Unikernels have thus far seen limited production deployment. This project aims to turn the Linux kernel into a unikernel with the following characteristics: 1) easily compiled for any application, 2) uses battle-tested, production Linux and glibc code, 3) allows the entire upstream Linux developer community to maintain and develop the code, and 4) provides applications normally running vanilla Linux to benefit from unikernel performance and security advantages. The paper Unikernels: The Next Stage of Linux’s Dominance was presented at HotOS XVII, The 17th Workshop on Hot Topics in Operating Systems, 2019.
1:00 - 1:30 PM (EDT)
Porting Finite State Automata Traversal from GPU to FPGA: Exploring the Implementation Space
Speakers: Marziyeh Nourian and Michela Becchi, North Carolina State University
Conversation Leader from Red Hat: Ahmed Sannaulah
Show the abstract
While FPGAs have been traditionally considered hard to program, recently there have been efforts aimed to allow the use of high-level programming models and libraries intended for multi-core CPUs and GPUs to program FPGAs. For example, both Intel and Xilinx are now providing toolchains to deploy OpenCL code onto FPGA. However, because the nature of the parallelism offered by GPU and FPGA devices is fundamentally different, OpenCL code optimized for GPU can prove very inefficient on FPGA, in terms of both performance and hardware resource utilization.
We explored this problem on finite automata traversal. In particular, we consider an OpenCL NFA traversal kernel optimized for GPU but exhibiting FPGA-friendly characteristics, namely: limited memory requirements, lack of synchronization, and SIMD execution. We explore a set of structural code changes, custom, and best-practice optimizations to retarget this code to FPGA. We showcase the effect of these optimizations on an Intel Stratix V FPGA board using various NFA topologies from different application domains. Our evaluation shows that, while the resource requirements of the original code exceed the capacity of the FPGA in use, our optimizations lead to significant resource savings and allow the transformed code to fit the FPGA for all considered NFA topologies. In addition, our optimizations lead to speedups up to 4x over an already optimized code-variant aimed to fit the NFA traversal kernel on FPGA. Some of the proposed optimizations can be generalized for other applications and introduced in OpenCL-to-FPGA compiler.
Mostafa Eghbali Zarch, a PhD student at NCSU also working under the supervision of Dr. Michela Becchi, contributed to this work. Zarch’s research is focused on the exploration of different optimizations and scheduling methods on high-level synthesis tools for FPGAs, specifically OpenCL to FPGA SDKs.
1:30 - 2:00 PM (EDT)
Live Hardware Development at UCSC
Speaker: Jose Renau, University of California, Santa Cruz | CROSS
Conversation Leader from Red Hat: Karsten Wade
Show the abstract
Synthesis and simulation of hardware design can take hours before results are available, even for small changes. In contrast, software development embraced live programming to boost productivity. This article proposes LiveHD, an open-source incremental framework for hardware synthesis and simulation that provides feedback within seconds. Three principles for incremental design automation are presented. LiveHD uses a unified VLSI data model, LGraph, to support the implementation of incremental principles for synthesis and simulation. LiveHD also employs a tree-like high-level intermediate representation to interface modern hardware description languages. We present early results comparing with commercial and open source tools. LiveHD can provide feedback for synthesis, placement and routing in < 30s for most changes tested with negligible QoR impact. For the incremental simulation, LiveHD is capable of completing any simulation cycle in under 2s for a 256 RISC-V core design.
2:00 - 3:00 PM (EDT)
NETWORKING
* There will be joint Discussion Breakout Session for Kernel Techniques to Optimize Memory Bandwith with Predictable Latency and Unikernel talks, starting at 1:00 PM
Distributed Workflows
Sep 17
11:00 AM - 12:00 PM (EDT)
NETWORKING
11:50 AM - 12:00 PM (EDT)
Introduction from Research Director
by Hugh Brock
12:00 - 12:30 PM (EDT)
Learning from Biased and Small Datasets
Speaker: Kate Saenko, Boston University
Conversation Leader from Red Hat: Sherard Griffin
Show the abstract
Deep Learning has made exciting progress on many computer vision problems such as object recognition in images and video. However, it has relied on large datasets that can be expensive and time-consuming to collect and label. Datasets can also suffer from “dataset bias,” which happens when the training data is not representative of the future deployment domain. Dataset bias is a major problem in computer vision — even the most powerful deep neural networks fail to generalize to out-of-sample data. A classic example of this is when a network trained to classify handwritten digits fails to recognize typed digits, but this problem happens in many situations, such as new geographic locations, changing weather, and simulation-to-real learning. Can we solve dataset bias with only a limited amount of supervision? Yes, this is possible under some assumptions. I will give an overview of current solutions based on domain adaptation of deep learning models and point out several assumptions they make and situations they fail to handle. Finally, I will describe recent efforts to improve adaptation by using unlabeled data to learn better features, with ideas from self-supervised learning.
12:30 - 1:00 PM (EDT)
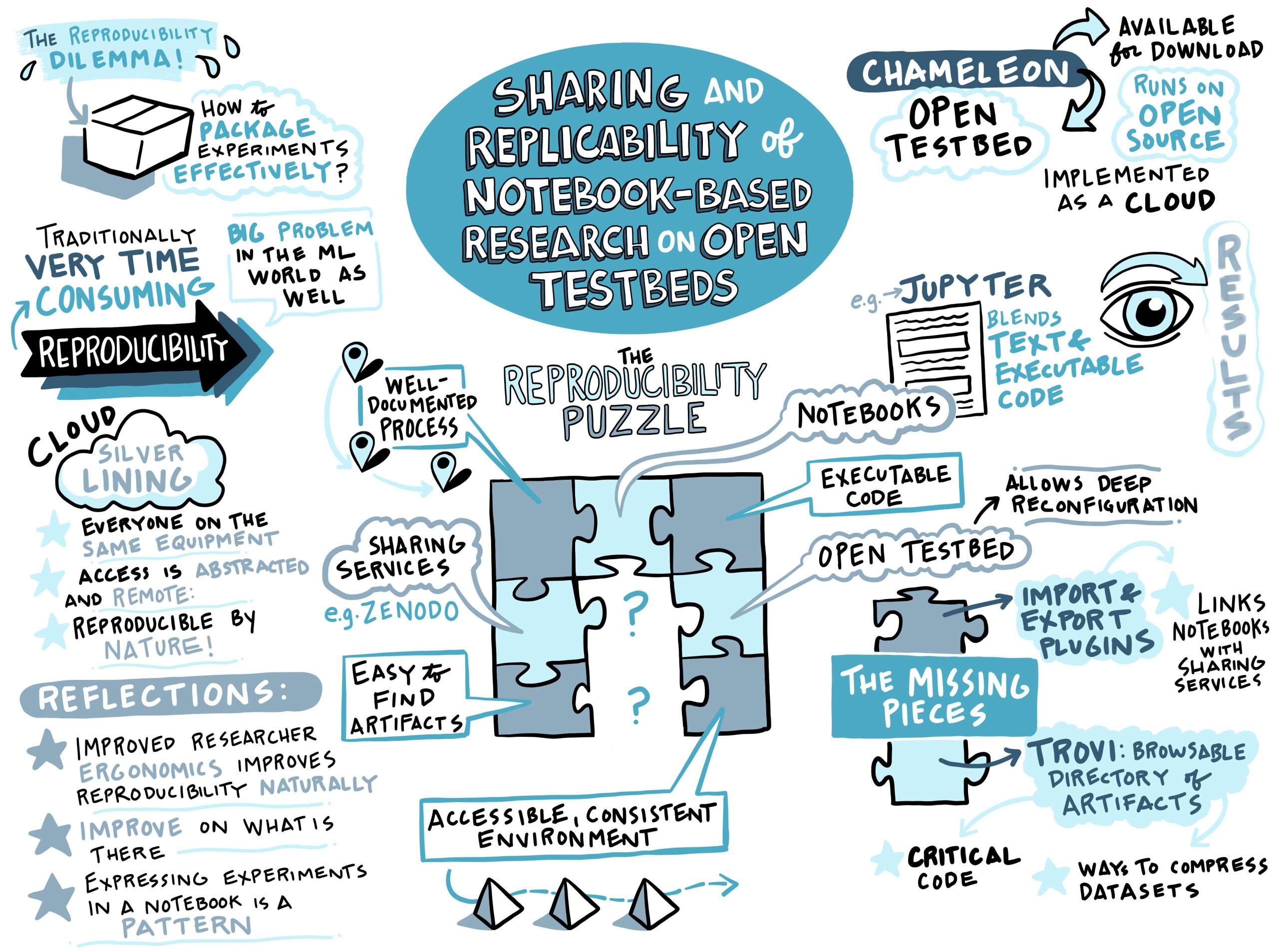
Sharing and Replicability of Notebook-Based Research on Open Testbeds
Speaker: Jason Anderson, University of Chicago
Conversation Leader from Red Hat: Juana Nakfour
Show the abstract
Ensuring that research can be reproduced, replicated, and repeated is critical to extending, building upon, and verifying that research. However, as research has gotten more advanced, creating experiments that can be easily replicated has gotten to be quite complicated. To effectively create a reproducible experiment, a researcher must be able to (1) run code in a consistent, customizable, powerful environment, (2) combine that code with process documentation, and (3) publish to a shared platform, where their experiment can be discovered and performed by others. Up until now, we have had ways to connect two of these at a time, but not to make a full picture. In this talk, we will discuss how we were able to create a sharing platform that keeps relevant research in one place, is easy to search, and makes it easy to get code in and out in order to replicate computer science experiments using notebooks on an open testbed, Chameleon.
1:00 - 1:30 PM (EDT)
Enabling Rapid, Reproducible Experimentation with Popper Container-Native Workflows
Speakers: Ivo Jimenez and Carlos Maltzahn, University of California, Santa Cruz | CROSS
Conversation Leader from Red Hat: Chris Wright
Show the abstract
Popper is a container-native workflow execution and task automation engine. In practice, when we work following the container-native paradigm, we end up interactively executing multiple docker pull|build|run commands in order to build containers, compile code, test applications, deploy software, etc. Keeping track of which docker commands we have executed, in which order, and which flags were passed to each, can quickly become unmanageable, difficult to document (think of outdated README instructions) and error prone. The goal of Popper is to bring order to this chaotic scenario by providing a framework for clearly and explicitly defining container-native tasks. You can think of Popper as a tool for wrapping all these manual tasks in a lightweight, machine-readable, self-documented format (YAML). In this talk we introduce Popper, a container-native workflow engine that does not assume the presence of a Kubernetes cluster or any cloud-based Kubernetes service. We discuss the design and architecture of Popper and how it abstracts away the complexity of distinct container engines (Singularity, Podman, Docker) and resource managers, enabling users to focus only on writing workflows. With Popper, researchers can build and validate workflows easily in almost any environment of their choice including local machines, SLURM-based HPC clusters, CI services (Travis, CircleCI, Jenkins, etc.), or Kubernetes-based cloud computing environments. To exemplify the suitability of this workflow engine, we present a case study from Machine Learning, and execute the same workflow on distinct platforms with minimal modifications.
1:30 - 2:00 PM (EDT)
FABRIC: Adaptive Programmable Research Infrastructure for Computer Science and Science Applications
Speaker: Ilya Baldin, University of North Carolina | RENCI
Conversation Leader from Red Hat: Jiří Benc
Show the abstract
FABRIC is a unique national research infrastructure to enable cutting-edge and exploratory research at-scale in networking, cybersecurity, distributed computing and storage systems, machine learning, and science applications.
It is an everywhere programmable nationwide instrument comprised of novel extensible network elements equipped with large amounts of compute and storage, interconnected by high speed, dedicated optical links. It will connect a number of specialized testbeds for cloud research (NSF Cloud testbeds CloudLab and Chameleon), for research beyond 5G technologies (Platforms for Advanced Wireless research or PAWR), as well as production high-performance computing facilities and science instruments to create a rich fabric for a wide variety of experimental activities.
More info at whatisfabric.net
2:00- 3:00 PM (EDT)
NETWORKING
Privacy
Sep 22
11:00 AM - 12:00 PM (EDT)
NETWORKING
Join us for a live networking discussion session with a member of Red Hat Research: Gagan Kumar
11:50 AM - 12:00 PM (EDT)
Introduction from Research Director
by Hugh Brock
12:00 - 1:00 PM (EDT)
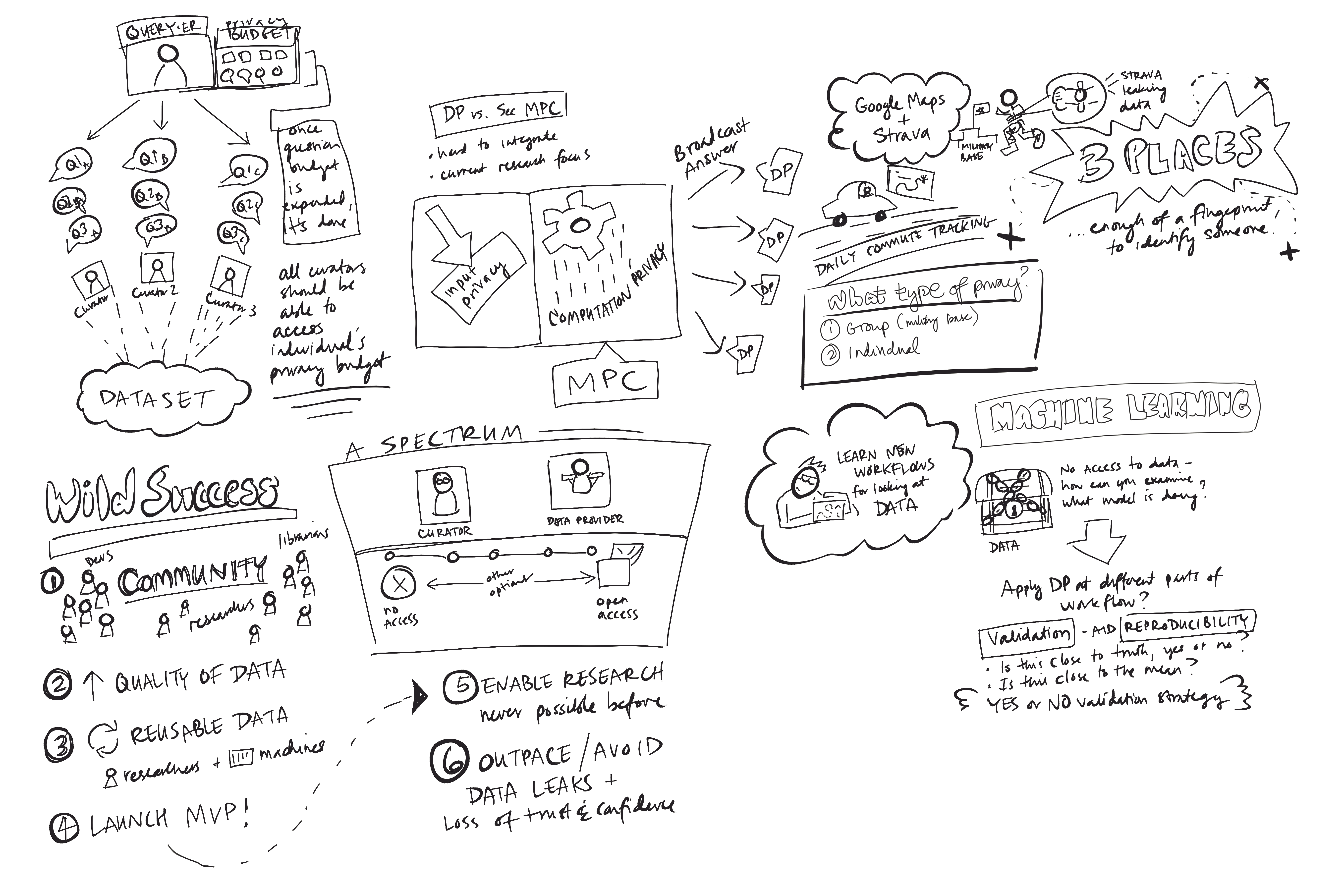
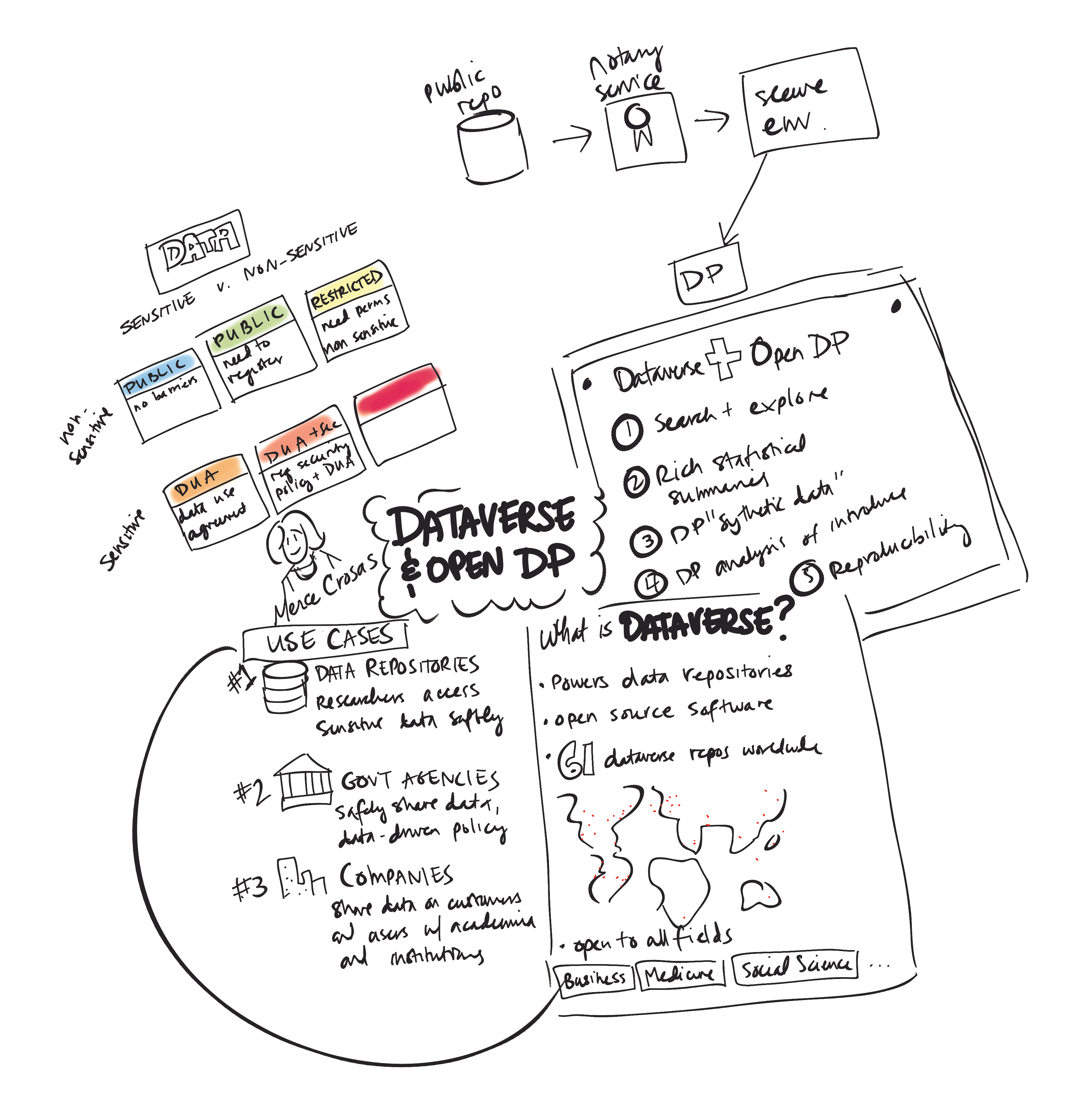
Dataverse and OpenDP: Tools for Privacy-Protective Analysis in the Cloud
Speakers: Mercè Crosas, Harvard University and James Honaker, Harvard University, Facebook
Conversation Leader from Red Hat: Chris Wright
Show the abstract
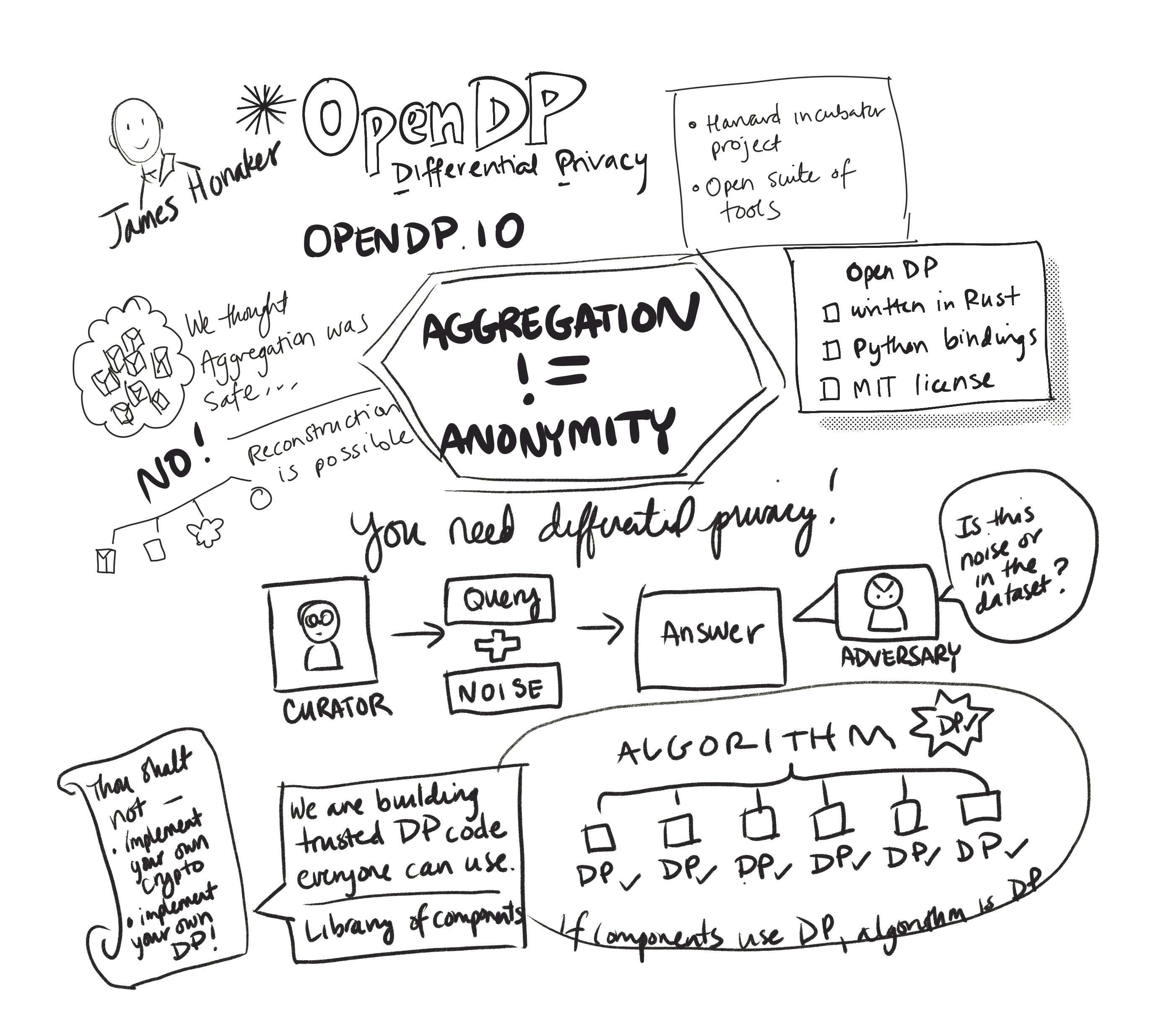
When big data intersects with highly sensitive data, both opportunity to society and risks abound. Traditional approaches for sharing sensitive data are known to be ineffective in protecting privacy. Differential Privacy, deriving from roots in cryptography, is a strong mathematical criterion for privacy preservation that also allows for rich statistical analysis of sensitive data. Differentially private algorithms are constructed by carefully introducing “random noise” into statistical analyses so as to obscure the effect of each individual data subject. OpenDP is an open-source project for the differential privacy community to develop general-purpose, vetted, usable, and scalable tools for differential privacy, which users can simply, robustly and confidently deploy.
Dataverse is an open source web application to share, preserve, cite, explore, and analyze research data. It facilitates making data available to others, and allows you to replicate others’ work more easily. Researchers, journals, data authors, publishers, data distributors, and affiliated institutions all receive academic credit and web visibility. A Dataverse repository is the software installation, which then hosts multiple virtual archives called Dataverses. Each dataverse contains datasets, and each dataset contains descriptive metadata and data files (including documentation and code that accompany the data).
This session examines ongoing efforts to realize a combined use case for these projects that will offer academic researchers privacy-preserving access to sensitive data. This would allow both novel secondary reuse and replication access to data that otherwise is commonly locked away in archives. The session will also explore the potential impact of this work outside the academic world.
1:00 - 1:30 PM (EDT)
Differential Privacy: Algorithms for Privacy-Conscious Customers and Users
Speaker: Adam Smith, Boston University
Conversation Leader from Red Hat: Mike Bursell
Show the abstract
Consider an agency holding a large database of sensitive personal information—say, medical records, census survey answers, web searches, or genetic data. The agency would like to discover and publicly release global characteristics of the data while protecting the privacy of individuals’ records. I will present differential privacy, a rigorous definition of privacy for such settings that is now widely studied, and increasingly used to analyze and design deployed systems. I’ll explain how this line of research might help share information about a data center’s operations in ways that protect clients’ interests, and discuss a few of the challenges that arise.
1:30 - 2:00 PM (EDT)
Building and Deploying a Privacy Preserving Data Analysis Platform
Speaker: Frederick Jansen, Boston University
Conversation Leader from Red Hat: Jayashree Ramanathan
Show the abstract
This talk focuses on our experience building and deploying various iterations of a web-based secure Multi-Party Computation (MPC) platform. Our experience demonstrates that secure computations can add value to questions of social good when otherwise constrained by legal, ethical, or privacy restrictions, and that it is feasible to deploy MPC solutions today.
2:00 - 3:00 PM (EDT)
NETWORKING
Infrastructure Software
Sep 30
11:00 AM - 12:00 PM (EDT)
NETWORKING
11:50 AM - 12:00 PM (EDT)
Introduction from Research Director
by Hugh Brock
12:00 - 12:30 PM (EDT)
Efficient Fuzzing with Neural Program Smoothing
Speaker: Baishakhi Ray, Columbia University
Conversation Leader from Red Hat: Bandan Das
Show the abstract
Fuzzing has become the de facto standard technique for finding software vulnerabilities. However, even state-of-the-art fuzzers are not very efficient at finding hard-to-trigger software bugs. Most popular fuzzers use evolutionary guidance to generate inputs that can trigger different bugs. Such evolutionary algorithms, while fast and simple to implement, often get stuck in fruitless sequences of random mutations. Gradient-guided optimization presents a promising alternative to evolutionary guidance. Gradient-guided techniques have been shown to significantly outperform evolutionary algorithms at solving high-dimensional structured optimization problems in domains like machine learning by efficiently utilizing gradients or higher-order derivatives of the underlying function. However, gradient-guided approaches are not directly applicable to fuzzing as real-world program behaviors contain many discontinuities, plateaus, and ridges where the gradient-based methods often get stuck. This problem can be addressed by creating a smooth surrogate function approximating the target program’s discrete branching behavior. In this session, we propose a novel program smoothing technique using surrogate neural network models that can incrementally learn smooth approximations of a complex, real-world program’s branching behaviors. We further demonstrate that such neural network models can be used together with gradient-guided input generation schemes to significantly increase the efficiency of the fuzzing process. Our extensive evaluations demonstrate that NEUZZ significantly outperforms 10 state-of-the-art graybox fuzzers on 10 popular real-world programs both at finding new bugs and achieving higher edge coverage. NEUZZ found 31 previously unknown bugs (including two CVEs) that other fuzzers failed to find in 10 real-world programs and achieved 3X more edge coverage than all of the tested graybox fuzzers over 24 hour runs. Furthermore, NEUZZ also outperformed existing fuzzers on both LAVA-M and DARPA CGC bug datasets.
12:30 - 1:00 PM (EDT)
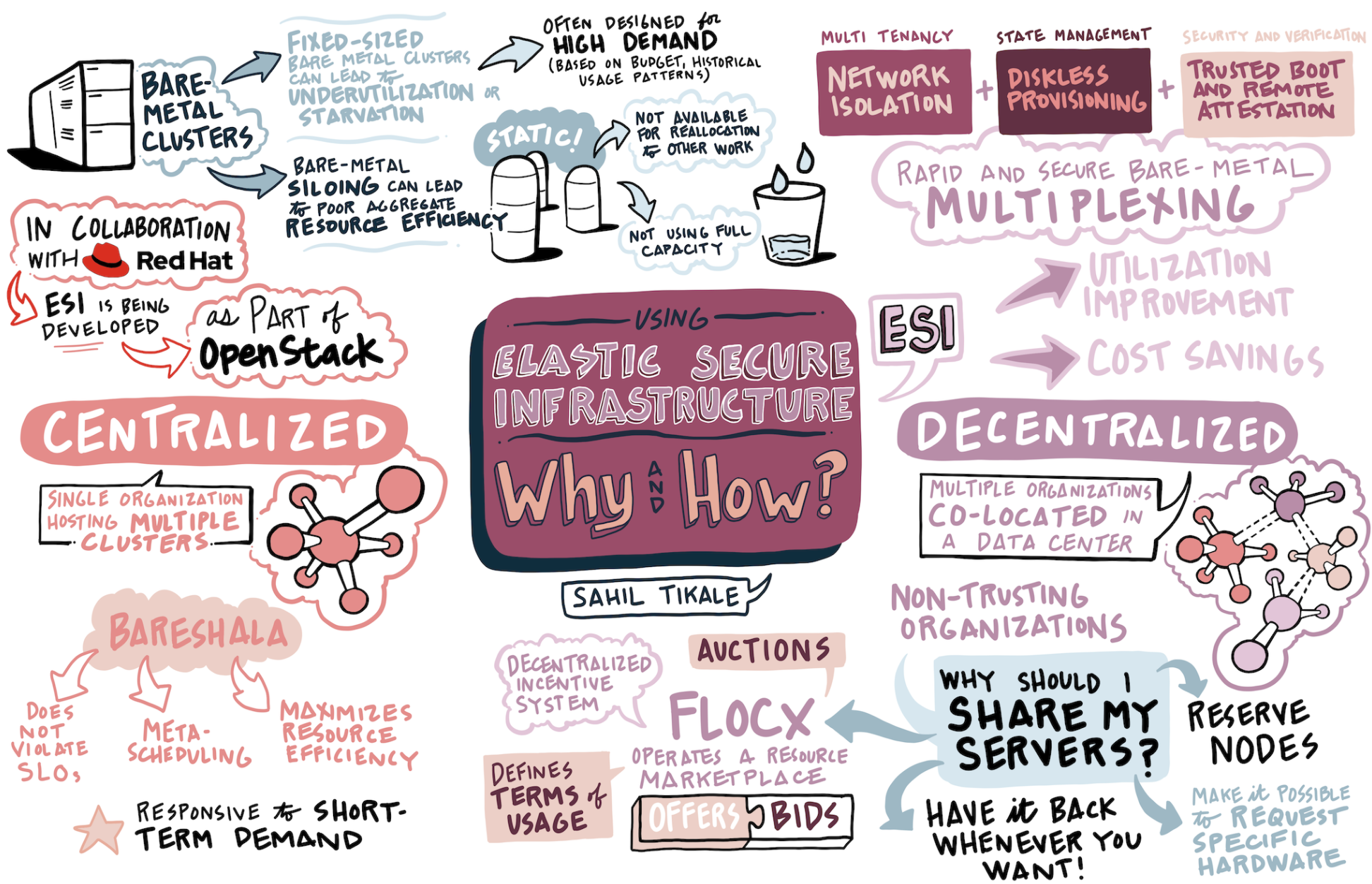
Using Elastic Secure Infrastructure: Why and How?
Speakers: Sahil Tikale, Boston University and Apoorve Mohan, Northeastern University
Conversation Leader from Red Hat: William Henry
Show the abstract
Today many organizations choose to host their physically deployed clusters outside of the cloud for security, price or performance reasons. Such organizations form a large section of the economy including financial companies, medical institutions and government agencies. Organizations host these clusters in their private data centers or rent a colocation facility. Clusters typically include sufficient capacity to deal with peak demand, resulting in silos of under-utilized hardware. Elastic Secure Infrastructure (ESI) is a platform, created at Massachusetts Open Cloud, that enables physically deployed clusters to break out of these silos. It enables rapid multiplexing of bare metal servers between clusters with different security requirements. In this talk we present BareShala and FLOCX, which leverage ESI to improve aggregate resource efficiency in centralized and decentralized environments respectively. BareShala is a system architecture for centralized bare metal resource management. An organization can use it to improve aggregate resource efficiency in its data center while ensuring that cluster service-level objectives (SLOs) are not violated. FLOCX is a decentralized market-based incentive system where organizations hosting clusters in a colocated data center can trade their servers to meet demand fluctuations. We will describe preferences and constraints of different clusters and how they can benefit from such a marketplace. We will discuss the economic model that drives the market followed by the initial design of the prototype.
1:00 - 1:30 PM (EDT)
Optimal Scheduling of Parallelizable Jobs in Multicore Systems to Minimize Average Latency
Speakers: Benjamin Berg and Mor Harchol-Balter, Carnegie Mellon University
Conversation Leaders from Red Hat: Bill Gray and Douglas Shakshober
Show the abstract
Modern multicore systems allow for the dynamic allocation of resources to parallelizable jobs. When a job is parallelized across many cores, it will complete more quickly. However, jobs typically receive diminishing returns from being allocated additional cores. Hence, given a fixed number of cores, it is not obvious how to allocate cores across a set of jobs in order to minimize the overall mean response time. A good allocation policy should favor shorter jobs, but favoring any single job too heavily can cause the system to operate very inefficiently. We derive the optimal allocation policy which minimizes mean response time across a set of jobs by balancing the trade-off between granting priority to short jobs and maintaining the overall efficiency of the system.
1:30 - 2:00 PM (EDT)
High-Performance Certified Trust for Cloud-Scale Enclaves
Speakers: Zhong Shao, Richard Habeeb and Hao Chen, Yale University
Conversation Leader from Red Hat: Nathaniel McCallum
Show the abstract
Modern hardware provides the ability to run programs in a trusted execution environment where code and data’s confidentiality and integrity is protected. On x86, for example, these include AMD’s SEV/SME and Intel’s SGX. Our project aims to leverage on our expertise in building certified operating system kernels[1] along with hardware enforced TEEs to build a formally verified trusted platform. In this proposal, we plan to specify a top-down formal model of a generic hardware enclave, which could further connect to a particular implementation, e.g., SGX, ARM TrustZone, and RISC-V counterparts. On top of this hardware enclave model, we plan to implement a formally verified OS kernel/hypervisor, as a mixed security monitor and runtime to provide improved management and interfaces for enclaves. With the help of an open-source hardware/software stack, and a certified execution environment, cloud users could move one step forward to deploy trusted applications on their in-house servers into cloud platforms.
2:00- 3:00 PM (EDT)
NETWORKING